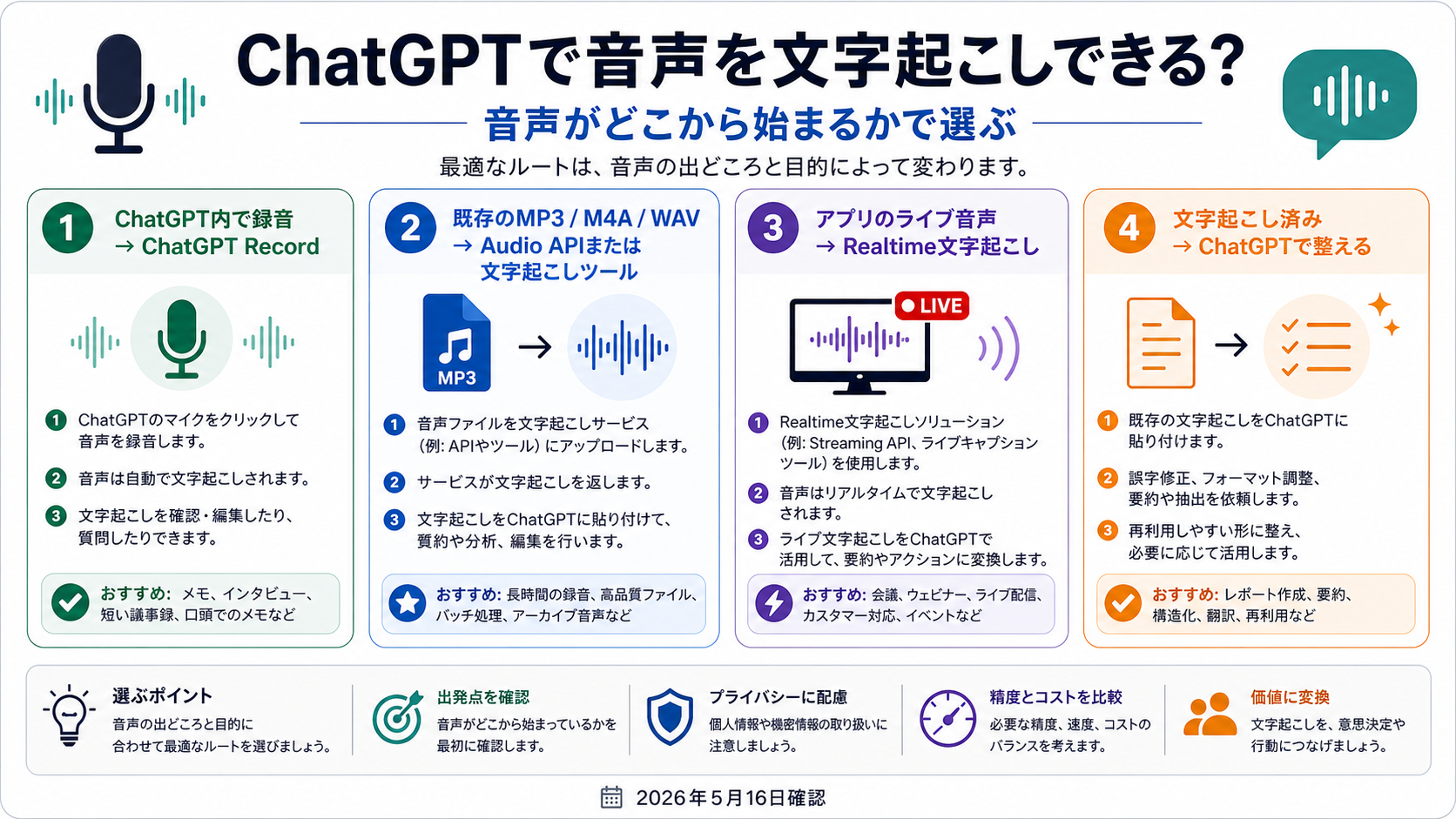
ChatGPTは音声文字起こしに関係する作業を助けられます。ただし、どんな音声ファイルでもそのまま普通のチャットに入れればよい、という意味ではありません。ChatGPTの対応したデスクトップ環境で今まさに録音しているならChatGPT Record、すでにMP3、M4A、WAV、ボイスメモがあるならOpenAI Audio APIか信頼できる文字起こしツール、話している最中にテキストが必要ならRealtime transcription、すでに文字起こし済みならChatGPTで要約、整形、翻訳、タスク抽出を行うのが自然です。
| いま持っているもの | 向いているルート | 勘違いしないこと |
|---|---|---|
| ChatGPT内でこれから録音する | ChatGPT Record | 古い音声ファイルをどのチャットにも投入できる |
| 短いプロンプトを声で入力したい | 音声入力 | 会議録のような文字起こしや話者ラベルが出る |
| 既存のMP3、M4A、WAV、ボイスメモがある | OpenAI Audio APIまたは文字起こしツール | 有料ChatGPTプランだけで音声ファイル転写が保証される |
| ファイル文字起こし機能を作る | /v1/audio/transcriptions | ライブストリーミングと同じ挙動になる |
| アプリでライブ音声をテキスト化したい | Realtime transcription | 録音済みファイルの一括アップロードに最適 |
| すでに transcript がある | ChatGPTで整形、要約、翻訳、アクション項目化 | 音声の転写自体がChatGPT内で行われた |
OpenAIはChatGPT Record、開発者向けAudio API、Realtime APIを別々に説明しています。つまり、ChatGPTのサブスクリプション、OpenAI API key、外部の文字起こしツールは同じ契約ではありません。2026年5月16日に確認した公開情報を前提に、使えるルートと危ない思い込みを分けます。
音声は通常のテキストプロンプトよりも扱いが重いデータです。会議、顧客通話、授業、医療や法律に関係する録音、周囲の人の声が入ったファイルでは、技術的にアップロードできるかより先に、録音と送信の許可、保存先、削除方法、レビュー責任を確認してください。
まず音声がどこにあるかを決める
「ChatGPTで音声を文字起こししたい」と言う読者は、実は別々の問題を持っています。会議をその場で録音したい人、手元のMP3やM4Aを文字起こししたい人、WhisperやOpenAI APIを使ってアプリを作りたい人、すでにある文字起こしを要約したい人が同じ言い方に集まります。
そのため、単純に「できます」と答えると、既存ファイルを普通のChatGPTチャットへ投げたい読者を誤らせます。OpenAIのChatGPT対応ファイルタイプのページは、2026年5月16日時点で文書、表計算、プレゼン、PDF、テキストなどの通常アップロード対象を説明しており、MP3やM4Aを一般的な音声文字起こし入口として保証しているわけではありません。
一方で「できない」と切り捨てるのも古い答えです。OpenAIにはChatGPT Recordのヘルプページがあり、開発者向けにはspeech-to-text guideとRealtime transcription guideがあります。正しい答えは、ChatGPTという名前を一つの入口として見るのではなく、音声がどの状態にあるかで選びます。
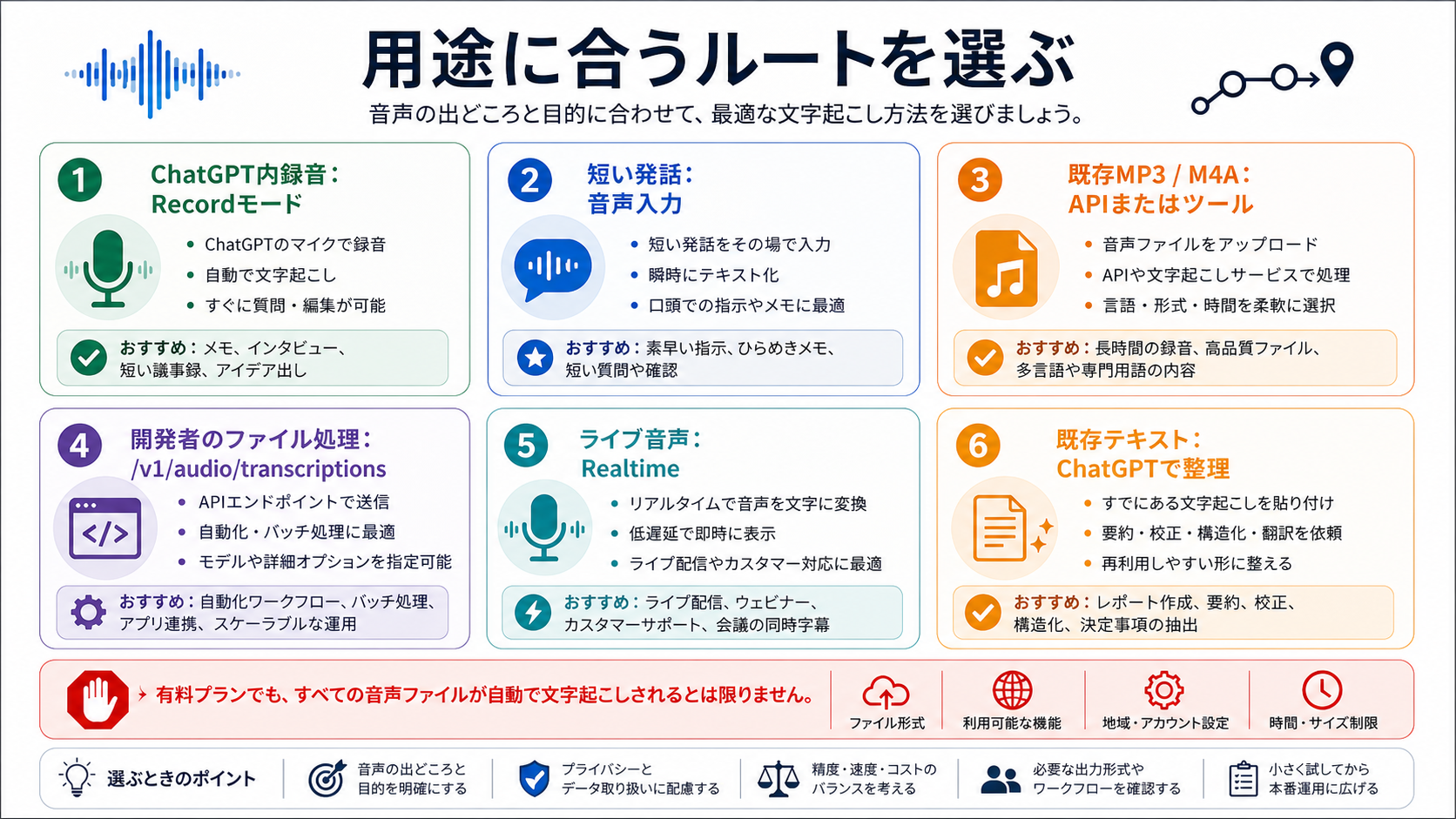
実務では四つに分けると迷いません。音声が今起きていて、対応したChatGPTデスクトップ環境にいるならRecord。音声がすでにファイルならAudio APIまたは文字起こしツール。製品内で発話中にテキストが必要ならRealtime。音声がすでにテキスト化されているならChatGPTで編集、要約、翻訳、タスク化を行います。
アカウントの所有者も分けてください。ChatGPTプランはChatGPT製品の機能を決めます。OpenAI API keyは開発者プロジェクトで呼べるエンドポイントとモデルを決めます。外部ツールはアップロード、保存、削除、料金、話者分離を自分の契約で決めます。この三つを「ChatGPTで文字起こし」と一括りにすると、失敗時の原因が見えなくなります。
ChatGPT Recordを使う場面
ChatGPT Recordは、対応したChatGPTアプリ内で音声を録音し、そのセッションからtranscript、summary、notesを作りたいときの製品ルートです。OpenAIのChatGPT Recordヘルプページは、2026年5月16日時点で、macOSデスクトップアプリのPlus、Pro、Business、Enterprise、Eduワークスペース向け機能として説明しています。
このルートは、会議、ブレインストーミング、インタビュー、音声メモなどのライブキャプチャに向いています。手元にある昔の音声ファイルを、どのChatGPTチャットにもドラッグできるという意味ではありません。Recordには固有の入口、マイク権限、ワークスペース制御、セッション上限、保存ルールがあります。
ヘルプページは現在、1セッション4時間の上限も示しています。ただし、プラン名、利用可能プラットフォーム、上限、価格のような情報は変わる可能性があります。自社マニュアルや公開記事に固定的な表現で書く場合は、その時点でヘルプを再確認してください。
Recordは複数話者を扱えますが、結果をそのまま事実として扱うべきではありません。人名、金額、日付、顧客の約束、専門用語、契約上の表現は、少しの誤認識でも影響が大きい部分です。顧客返信、契約メモ、医療・法律・支払い判断に使うなら、transcriptは必ず人間が確認する下書きとして扱います。
保存ルールもRecordを選ぶ理由の一部です。OpenAIはRecordの音声録音が転写に使われた後に削除されると説明し、生成されたcanvasやtranscriptは通常のconversationまたはcanvas retention設定に従うとしています。無料の文字起こしサイトへアップロードする場合とも、自社APIで処理してログやストレージに残す場合とも異なるデータの形です。
既存のMP3、M4A、WAV、ボイスメモがある場合
既存ファイルはもっとも誤解が多い分岐です。読者が本当に聞きたいのは「会議録音、授業、インタビュー、ポッドキャスト、ボイスメモをChatGPTに渡せるか」です。この場合、有料プランかどうかだけで判断せず、現在の製品入口が音声ファイルの転写を明確にサポートしているかを見ます。
一回だけの個人録音であれば、専用の文字起こしツールの方がAPIを書くより簡単かもしれません。ただし、簡単さは信頼の代わりにはなりません。運営者、保存期間、削除可否、学習利用の有無、長尺ファイルの分割、話者ラベルの扱い、無料枠の制限を確認してください。公開してもよい低リスク音声なら十分でも、顧客通話や社内会議には危険なことがあります。
繰り返し使うならOpenAI Audio APIの方が明確です。エンドポイント、モデル、レスポンス形式、ログ境界、リトライ、DB連携を自分で設計できます。ファイル名、時間、モデル、レスポンス形式、リクエスト時刻、リトライ回数、transcript version、レビュー状態を残せるので、後から検証しやすくなります。
ChatGPTでファイルが失敗したときは、同じアップロードを何度も繰り返さないでください。まず、その製品画面が本当に音声ファイル転写をサポートしているかを確認します。次に、形式、サイズ、長さ、ワークスペースルール、サービス状態を見ます。業務上重要な音声なら、偶然うまくいくチャット入口を探すのではなく、制御できる文字起こしルートへ移します。
| ファイルの状態 | 取るべき対応 | 事前に見ること |
|---|---|---|
| 個人用の低リスク音声メモ | 文字起こしツールまたは小さなAPIスクリプト | 保存、削除、長さ、無料枠 |
| 顧客通話や社内会議 | 承認済みツールまたは自社API workflow | 同意、監査、保存先、レビュー責任者 |
| 授業、ポッドキャスト、長尺アーカイブ | Audio APIを使ったキューと分割 | サイズ制限、コスト、再試行、版管理 |
| ほしいのは要約だけ | 先に転写してからChatGPTへテキストを渡す | 要約と転写を混同しない |
完成済みファイルにはAudio APIを使う
入力が完成済みの音声ファイルで、出力をアプリ、DB、ワークフロー、顧客システムに渡したいなら、OpenAI Audio APIが開発者向けの自然な入口です。現在のspeech-to-text guideは、/v1/audio/transcriptionsを文字起こし、/v1/audio/translationsを英語への音声翻訳として説明しています。

ファイル転写の流れはシンプルです。対応音声ファイルをアップロードし、転写モデルを選び、テキストまたはJSONを受け取り、その後の処理へ渡します。2026年5月16日時点のguideでは、標準アップロード形式としてmp3、mp4、mpeg、mpga、m4a、wav、webmが示され、通常アップロードの境界として25 MBが書かれています。形式、サイズ、モデル名、パラメータ対応は変わり得るため、顧客アップロードを受ける前に再確認してください。
モデル選択は人気順ではなく、出力要件から決めます。guideにはgpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-transcribe-diarize、whisper-1が並びます。音声がきれいでコストや速度が重要なら軽いルート、精度が重要なら強いルート、話者ラベルが重要ならdiarizationルートを検討します。ただし、タイムスタンプ、streaming、speaker labelsが全モデルで同じとは考えないでください。
最小のJavaScript例は次の形です。
jsimport OpenAI from "openai"; import fs from "node:fs"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const transcript = await client.audio.transcriptions.create({ model: "gpt-4o-mini-transcribe", file: fs.createReadStream("meeting.m4a"), response_format: "json", }); console.log(transcript.text);
本番ではこの一呼び出しだけでは足りません。元ファイル名、録音時間、モデル、レスポンス形式、リクエスト時刻、リトライ回数、失敗理由、レビュー状態を残してください。顧客向け要約やアクション項目に使うなら、人間が確認したかどうかも状態として持つべきです。
APIを使う場合でも、OpenAI直結、クラウドプラットフォーム、企業プロキシ、外部ゲートウェイを同じものとして扱わないでください。ゲートウェイは接続の摩擦を下げることがありますが、請求、制限、モデル対応、ログ、サポートは別の契約です。そこで音声ファイルが処理できたからといって、普通のChatGPTチャットでも同じファイルが処理できるとは限りません。
ライブ音声にはRealtime transcriptionを使う
Realtime transcriptionは、すでに完成したファイルではなく、今流れている音声を扱うルートです。字幕、通話メモ、音声エージェント、アプリ内speech-to-text、会議アシスタントのように、発話中にテキストが必要な場合に向いています。OpenAIのRealtime transcription guideは、transcription sessions、transcript delta events、遅延と精度のトレードオフ、低遅延のgpt-realtime-whisperルートを説明しています。
実装の考え方はファイル転写と違います。完成済みファイルをアップロードして最終結果を待つのではなく、sessionを開き、音声をstreamし、incremental transcript eventsを受け取り、partial、修正、無音、発話区切り、切断時の回復を扱います。ライブ体験には強い一方、信頼性設計は複雑になります。
Realtimeを使うべきなのは、遅延が本当に問題になる場合です。古い講義、ポッドキャスト、ボイスメモ、会議録音をまとめて処理するなら、ファイルエンドポイントの方がデバッグしやすく、コストも読みやすいことが多いです。リアルタイム字幕、会議中の補助、音声アプリならRealtimeが自然です。
2026年5月7日にOpenAIはGPT-Realtime-Whisperを紹介し、その後OpenAI Statusには5月7日から8日にかけてChatGPTとCodexに影響した転写失敗インシデントが解決済みとして記録されました。これは今日の障害原因ではありませんが、複数の正常入力、複数アカウント、複数ルートが同時に失敗するときは、ワークフローを書き換える前にステータスを見るべきです。
文字起こし後の整理にはChatGPTが強い
ChatGPTが音声を直接テキスト化しない場合でも、transcriptができた後の処理では非常に強い道具になります。既存音声ファイルの実務では、まず制御できるルートで文字起こしし、そのテキストをChatGPTに渡す方が安全で明確です。
よくある後処理は次の通りです。
- 口癖や重複を消しながら意味を保つ
- 短い要約、詳細な議事録、上司向けブリーフを作る
- 決定事項、リスク、担当者、期限を抽出する
- 会議内容を顧客メールやプロジェクトメモに変える
- 発言意図を保ったまま翻訳する
- 時間付きtranscriptから引用や根拠を探す
- 二つのtranscriptを比較して約束や表現の変化を見る
この段階ではChatGPTのサブスクリプションが役立ちます。普通の音声ファイルアップロードが安定した転写入口でなくても、テキスト化された後ならChatGPTは推論、整理、書き換え、構造化、追加質問に強いからです。ただし、transcriptを整理したことを、ChatGPTが元の音声を普通のチャット内で転写した証拠として書かないでください。
機密性のあるtranscriptは、貼り付ける前に情報を削ってください。氏名、電話番号、支払い情報、医療・法律情報、顧客固有情報など、相手に不要なものは除きます。顧客、雇用主、学校、クライアントの録音であれば、その関係に適用されるポリシーを優先します。
アップロード前の安全性と信頼性チェック
音声には声紋、背景の名前、顧客情報、健康情報、金銭情報、子ども、同席者、録音に同意していない人が入ることがあります。正しいルートとは、動くルートであるだけでなく、使ってよいルートでもあります。

| 確認項目 | 録音またはアップロード前に問うこと |
|---|---|
| 同意 | この会話を録音し、文字起こしサービスへ送ってよいか |
| 機密性 | 規制対象、個人情報、顧客情報、法律、財務、医療、社内機密が含まれるか |
| ルート所有者 | ChatGPT Record、OpenAI API、外部アプリ、社内ツールのどれで、保存と削除を誰が管理するか |
| レビュー | 氏名、数字、話者ラベル、引用、アクション項目を誰が確認してから使うか |
信頼性も同じように切り分けます。ノイズ、かぶり発話、アクセント、小さい音量、音楽、専門用語、複数話者があると、見た目は整った誤りが出ます。不確かな語を明示させ、重要な決定は音声と照合し、話者ラベルは必ず確認してください。
転写が急に失敗したら、一度に一つだけ変数を変えます。短いファイル、単純な形式、きれいな録音、新しいsession、別ルート、ステータスページを順に試します。複数のきれいなテストが同時に失敗するならサービス状態かもしれません。一つのファイルだけ失敗するならファイル側の問題が濃厚です。ChatGPT製品ルートだけ失敗してAPIが通るなら、問題は製品入口であってOpenAIの音声転写全体ではありません。
よくある質問
ChatGPTはMP3を直接文字起こしできますか?
普通のChatGPTファイルアップロードを安定したMP3文字起こし入口として扱わないでください。ChatGPT Recordは対応した製品画面で録音した音声を扱い、OpenAI Audio APIは開発者ルートでアップロード音声を転写します。すでにMP3があるなら、現在のChatGPT sessionが明確に音声ファイル機能を提供していない限り、Audio APIまたは信頼できる文字起こしツールを使います。
ChatGPT Recordは無料ですか?
2026年5月16日に確認したRecordヘルプページは、Plus、Pro、Business、Enterprise、EduワークスペースとmacOSデスクトップアプリを示しています。これは現在の製品資格であり、恒久的な価格約束ではありません。プラン、プラットフォーム、上限を書く前に必ず最新情報を確認してください。
音声入力と文字起こしは同じですか?
違います。音声入力は、短く話した内容をチャット入力欄のテキストに変えるものです。会議文字起こしやファイル文字起こしは、録音をtranscriptに変え、話者、時刻、整形、レビューが必要になることがあります。この違いを混同すると、単純な「できる」が読者を誤らせます。
開発者はどのOpenAIモデルを使えばよいですか?
出力要件から決めます。新しいspeech-to-textルートなら現在のgpt-4o系転写モデル、コストと速度ならmini、話者ラベルが重要ならdiarizationモデル、既存の翻訳やタイムスタンプ挙動に依存するならwhisper-1も確認します。モデル名とパラメータ対応は変わるため、実装前に最新guideを見ます。
OpenAIはライブ音声をリアルタイムに文字起こしできますか?
できます。ただし完成済みファイルのエンドポイントではなく、Realtime transcriptionを使います。Realtimeはsessionに音声をstreamし、会話が続いている間にtranscript eventsを返します。字幕、ライブアシスタント、アプリ内speech-to-textに向いています。
ChatGPTにtranscriptを渡して要約できますか?
できます。音声がテキストになった後なら、ChatGPTは要約、整形、翻訳、アクション項目抽出、メール下書き、バージョン比較を行えます。ただし、transcriptの要約は、ChatGPTが元の音声を普通のチャットで転写したこととは別です。
転写が急に失敗したら何を見ればよいですか?
まずルートを特定します。ChatGPT Recordならアプリ、ワークスペース、マイク権限、OpenAI Status。既存ファイルなら形式、長さ、サイズ、入口の対応。APIならモデル、エンドポイント、レスポンス形式、リクエスト時刻、エラーを記録します。複数の正常テストが同時に失敗するなら、構成変更の前にステータスページを見ます。