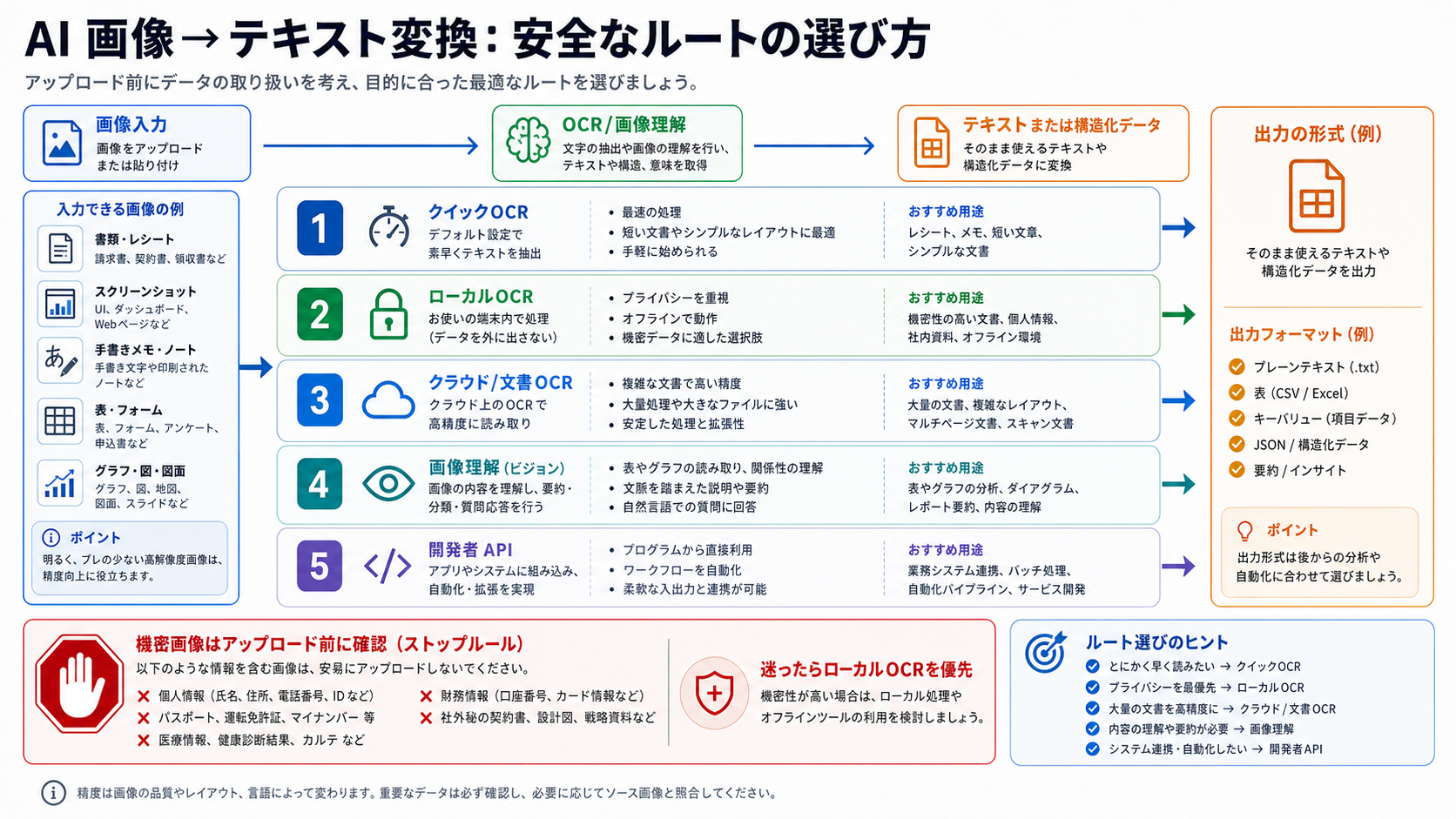
画像を文字に変換したいとき、最初に決めるべきことは「どのツールが速いか」ではありません。その画像を外部サービスへアップロードしてよいかどうかです。公開済みのメニュー、商品ラベル、低リスクの画面キャプチャなら、オンラインOCRから始めても問題になりにくいでしょう。一方で、契約書、顧客の請求書、医療情報、財務資料、本人確認書類、未公開プロダクトの画面は、ローカルOCRか、社内で確認済みの安全な処理ルートを先に選ぶべきです。
| 画像や作業の種類 | 先に選ぶルート | 理由 |
|---|---|---|
| 公開スクリーンショット、メニュー、ラベル、短いスキャン | オンラインOCRまたは軽量OCR | 低リスクで、ほしい出力はほぼプレーンテキスト。 |
| 顧客、法務、医療、財務、本人確認、未公開資料 | ローカルOCRまたは確認済みの私的ルート | 便利さよりアップロード境界が重要。 |
| 請求書、領収書、フォーム、ページスキャン、複数ファイル | 文書OCRまたはクラウドOCR | レイアウト、項目、表、ページ順、再現性が必要。 |
| 手書き、表、グラフ、数式、密なUIスクリーンショット | 画像理解モデル | 文字だけでなく文脈や構造を読む必要がある。 |
| プロダクト機能、バックエンド処理、自動化 | API | 認証、ログ、再試行、料金、データ境界、出力スキーマを明示できる。 |
アップロード前に出力形式も決めます。プレーンテキスト、Markdown表、CSV、JSON項目、LaTeX、alt text、短い画像説明のどれが必要なのかを先に指定してください。最初の抽出結果は完成版ではなく下書きです。金額、日付、氏名、ID、表の合計、読みにくい手書きは、必ず元画像と照合します。
画像の文字起こしは生成ではなく抽出
日本語で「AI 画像」「画像生成」「画像 文字起こし」が混ざると、画像を作るサービスと、画像から文字を取り出すサービスが同じもののように見えてしまいます。しかし方向は逆です。画像生成はテキストから新しい画像を作ります。画像の文字起こしは、既存の画像からテキスト、項目、表、説明、または画像に関する回答を取り出します。
この違いは実務上大きいです。画像生成では品質、著作権、スタイルの制御が主な論点になります。画像から文字を取り出す場合は、元ファイルの持ち主、アップロード先、保存や削除、学習利用の可能性、出力の検証方法まで考える必要があります。
きれいな印刷文字や短いラベルなら、通常のOCRが一番堅実です。斜めに撮った領収書や請求書なら、文字認識だけでなく、行項目、合計、通貨、日付、ページ順の保持が必要になります。グラフ、ダッシュボード、手書きメモ、数式、複雑なUI画面では、文字の一部を読むだけでは足りません。画像理解モデルは文脈や構造を説明できますが、推測や要約も行うため、検証の手順を強く持つ必要があります。
つまり、プロ向けの使い方は「一番よい変換サイトを探す」ことではありません。画像をアップロードできるか、画像の難しさは何か、どの形式で受け取りたいか、どこを人間が確認するかを先に決めることです。
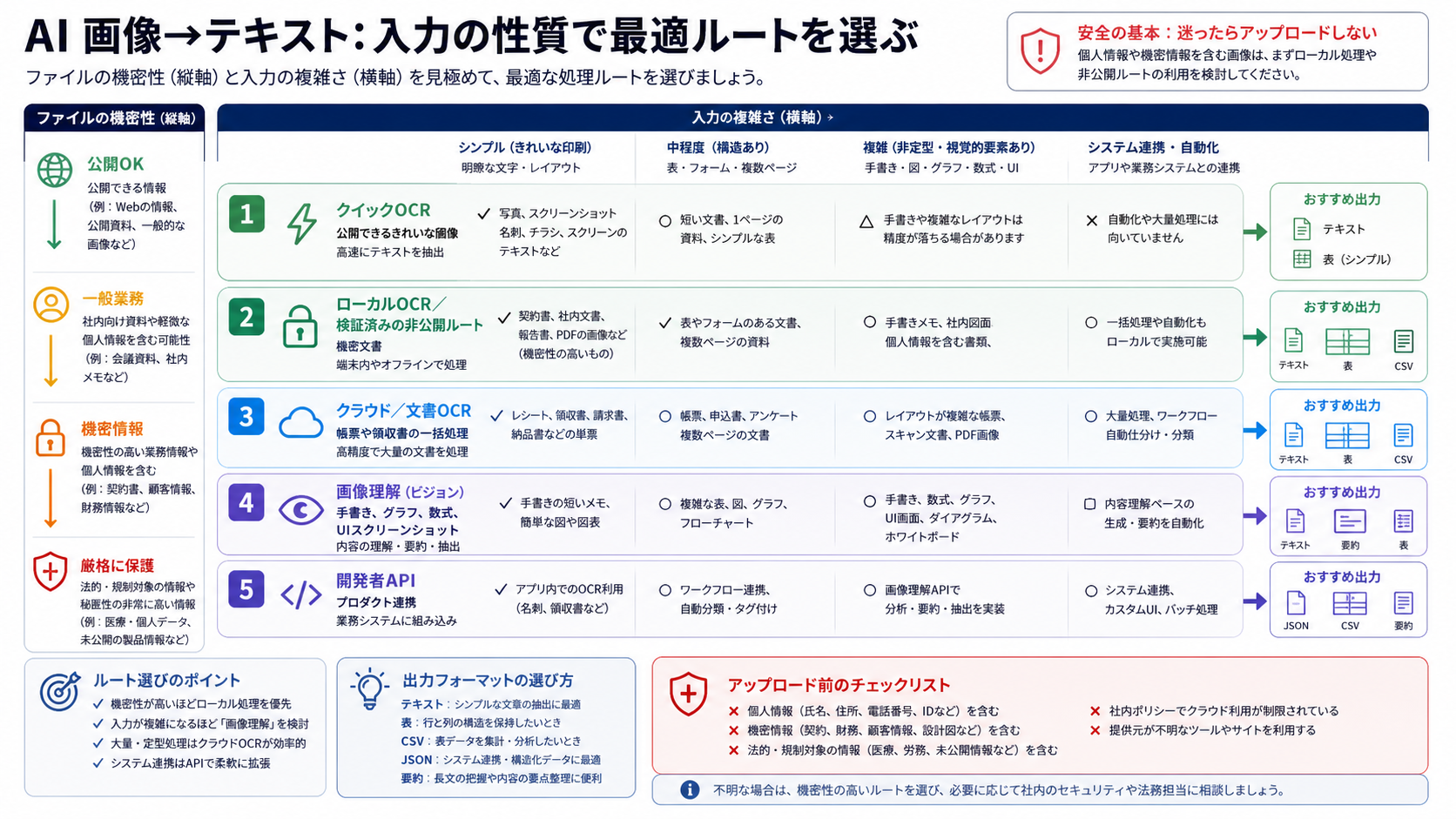
入力タイプで先に分ける
同じ画像ファイルでも、きれいなスクリーンショットと、折れた紙の写真では必要な処理が違います。入力タイプを見ずにツール名だけで選ぶと、単純な作業に過剰なモデルを使ったり、逆に難しい画像を軽いOCRで処理して失敗したりします。
| 入力タイプ | 向いている最初のルート | 依頼する出力 |
|---|---|---|
| きれいな印刷文字、ラベル、単純なスクリーンショット | オンラインOCRまたはローカルOCR | 改行を保ったテキスト |
| スキャン文書、請求書、領収書、フォーム | 文書OCRまたはクラウドOCR | 項目、表の行、ページ順、合計、信頼度メモ |
| 手書きや混在メモ | 画像理解モデルと目視確認 | 書き起こし、不確かな語のマーク |
| スクリーンショット内の表やPDF画像 | OCRと構造化出力 | Markdown表、CSV、JSON行 |
| グラフ、ダッシュボード、図、UI画面 | 画像理解モデル | タイトル、軸、凡例、見える値、読み取れる結論 |
| 数式や技術表記 | 画像理解モデルに形式指定 | LaTeX、コードブロック、段階的な転記 |
| アクセシビリティ用の画像説明 | alt textまたは長い説明 | ページ文脈に合わせた目的ベースの説明 |
通常のOCRは、見えている文字を正確に移す作業に向いています。文書OCRは、レイアウト、複数ページ、表、フォーム項目を保ちたいときに向いています。画像理解モデルは、画像が問いを含む場合に向いています。たとえば、エラー画面の次の操作、グラフが示す傾向、UIの状態、手書きの曖昧さ、表の意味を扱う場合です。
特定のプラットフォームを使う場合でも、この分類を先に行うほうが安全です。GeminiやOpenAIなどの画像入力機能を使う前に、仕事が文字認識なのか、文書処理なのか、視覚的な説明なのかを切り分けてください。
アップロードできる画像かを先に確認する
無料の変換ページは便利ですが、プライバシーポリシーの代わりにはなりません。公開済み資料や低リスク画像なら使えることがあります。しかし、契約書、医療資料、財務明細、顧客情報、社員情報、本人確認書類、法的証拠、未公開の画面を、運営者も保存条件もよく分からないページへ投げるのは危険です。
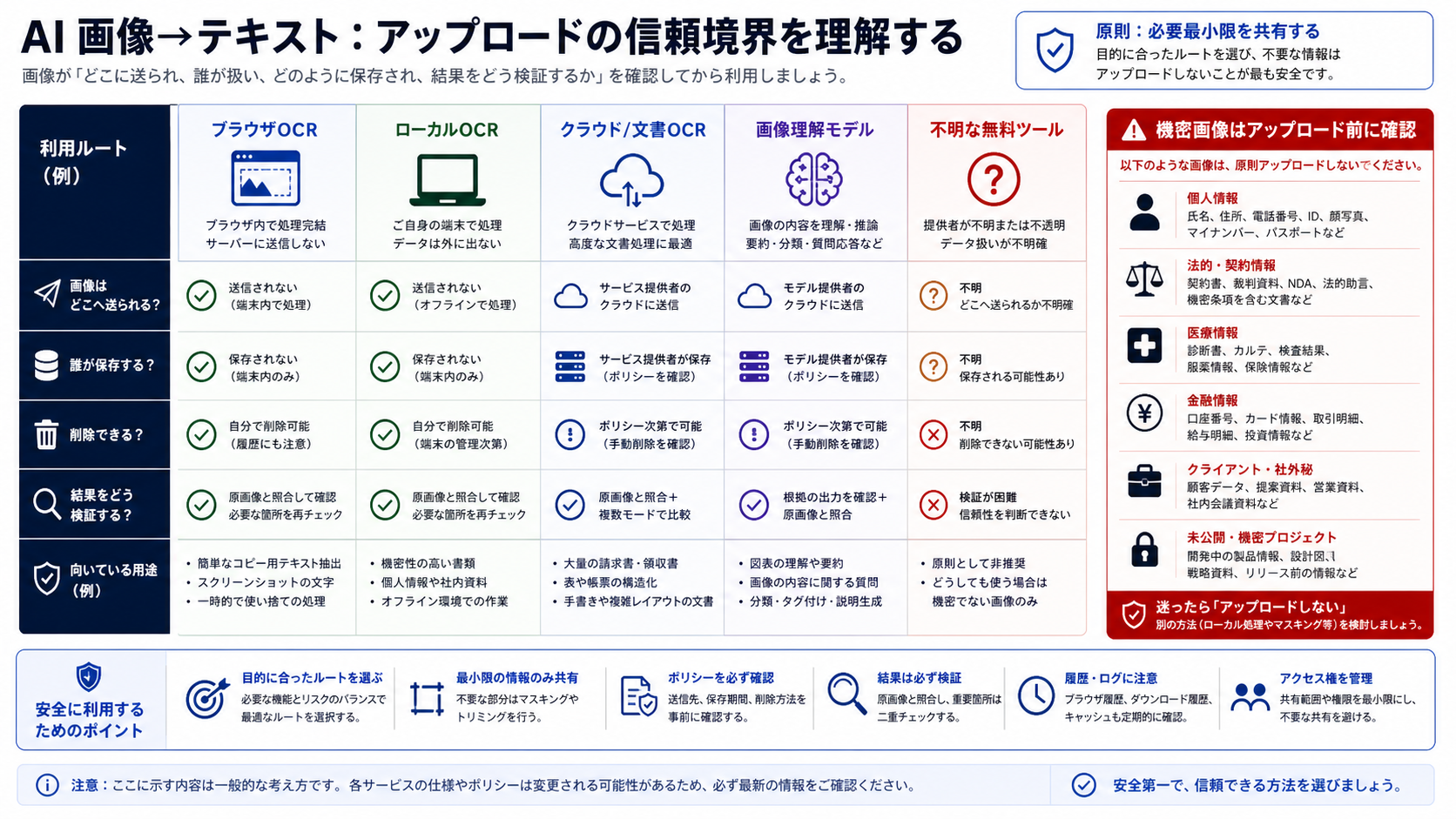
簡単な停止ルールを持つと判断しやすくなります。その画像が間違ったメールやチャットに流れたら問題になるなら、不明なサービスに先にアップロードしない。サービス運営者、画像の保存、削除方法、学習利用、権利の扱い、サポート責任を確認します。答えが不明なら、ローカルOCR、承認済みクラウド、社内の私的処理を先に選びます。
ローカルOCRは万能ではありませんが、信頼境界を自分側に寄せられます。TesseractのようなOCRエンジンや、そのラッパーを使うと、適した画像を自分の端末や管理環境内で処理できます。代わりに、言語データ、傾き補正、コントラスト、画像の切り抜き、表の確認など、品質管理は自分で持つ必要があります。
クラウドOCRや文書インテリジェンスはファイルを外部へ送りますが、アカウント、権限、ログ、リージョン、サポート、削除、課金を確認しやすいという利点があります。見知らぬ無料ページよりも、明示された契約を持つサービスのほうが、本番運用では扱いやすい場合が多いです。
必要な出力を先に指定する
「文字を抽出して」とだけ頼むと、後で使いにくい長文ブロックが返ることがあります。次に何をしたいのかを先に決めて、出力形式を指定しましょう。読むだけなら改行付きテキスト。スプレッドシートへ入れるならCSVやMarkdown表。請求書ならJSON項目。画面説明なら可視テキスト、UI状態、次に取る操作。グラフならタイトル、軸、凡例、見える数値、読み取れる傾向です。
使いやすい依頼文は次のような形です。
text画像内の見える文字を正確に抽出してください。改行を保ち、読めない語は [不明] としてください。
text画像内の表をMarkdown表にしてください。元の見出しを保ち、見えないセルを推測しないでください。
text請求書項目をJSONで返してください: vendor, invoice_number, date, subtotal, tax, total, currency, line_items。見えない項目はnullにしてください。
textこのグラフを見られない読者向けに説明してください。タイトル、軸、凡例、見える値、傾向、不確かな点を含めてください。
textこの画像のalt textを書いてください。ページ内で画像が伝える目的と情報を中心にしてください。
alt textは単なるOCRではありません。アクセシビリティの説明は、その画像がページで何を担っているかによって変わります。装飾画像なら空のaltが適切なこともあります。グラフなら短いaltと長い説明が必要かもしれません。証拠として使うスクリーンショットなら、見える文字とその意味を伝える必要があります。
抽出結果はそのまま使わない
OCRも画像理解モデルも、典型的な間違いをします。0とO、1とl、マイナス記号、小数点、表の列、結合セル、手書きの固有名詞、日付、金額などは特に危険です。モデルの文章が自然でも、元画像に忠実とは限りません。
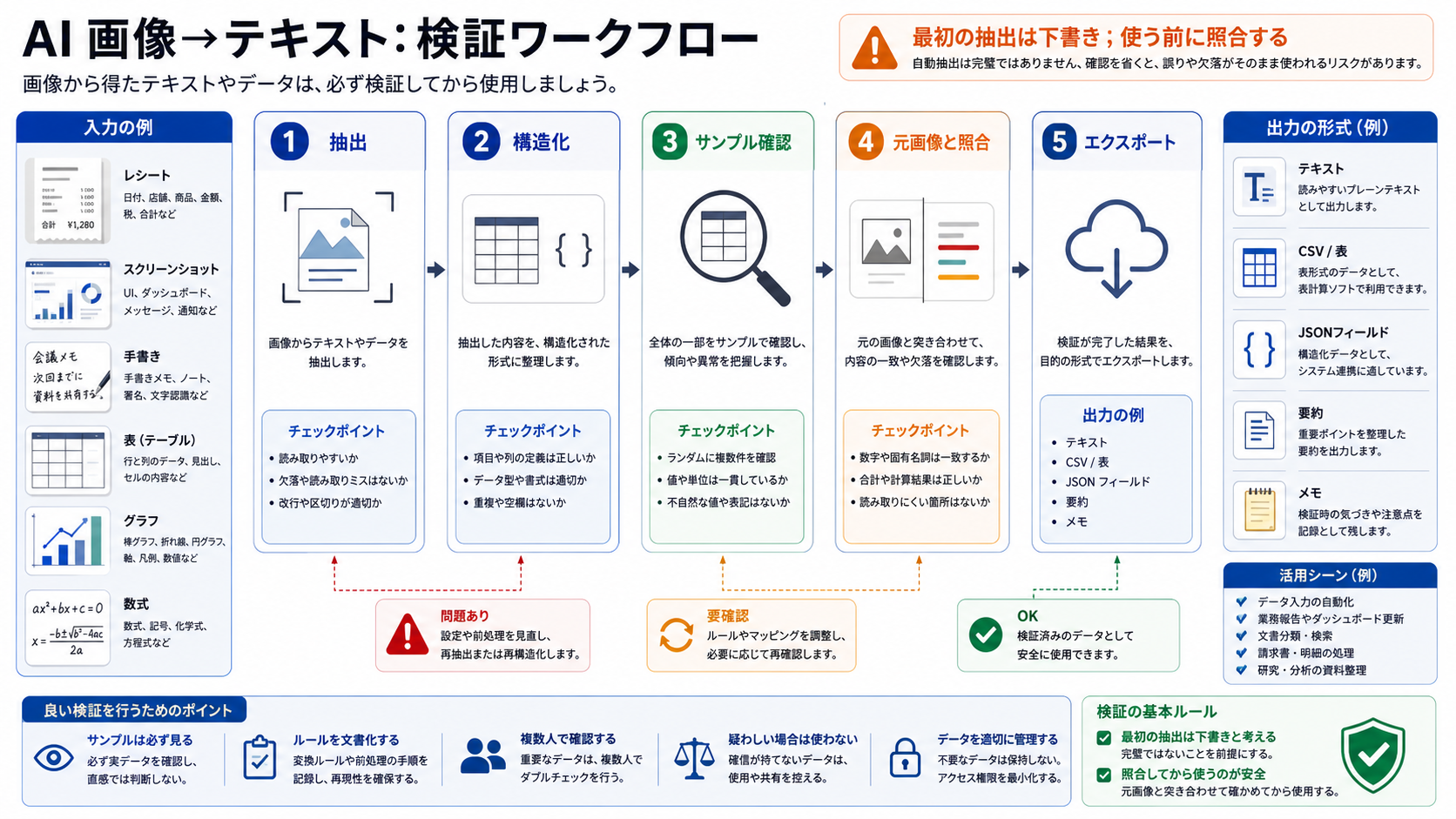
プレーンテキストなら、最初と最後の行、数字、氏名、ID、日付を確認します。表なら、見出し、中央の行、最後の行、合計を確認します。請求書や領収書なら、小計、税、合計、通貨を計算し直します。手書きなら、不確かな語を明示させ、重要部分を人間が確認します。
重要なファイルでは、二つ目のルートを使うと判断しやすくなります。ローカルOCRと画像理解モデルは、違う失敗をすることが多いです。日付、合計、行項目が一致すれば安心材料になります。不一致があれば、人間が見るべき箇所が明確になります。
業務で使うなら、軽い確認記録も残します。元画像、処理ルート、プロンプトや設定、確認した項目、確認者、日付を記録しておくと、後から結果を説明しやすくなります。公開スクリーンショットなら過剰かもしれませんが、法務、経理、顧客対応、運用では実用的です。
繰り返し処理ならAPIを使う
一回だけの公開画像ならブラウザ変換でも十分です。しかし、画像文字起こしがプロダクト、社内業務、カスタマーサポート、経理処理、自動化に入るなら、APIまたは社内パイプラインに移したほうが安全です。APIでは、認証、ログ、再試行、上限、費用、保存、削除、出力スキーマを明示できます。
| 本番で必要なこと | 向いているルート | 定義すること |
|---|---|---|
| 大量の印刷文字やラベル | OCR API | 前処理、言語ヒント、信頼度、再試行 |
| スキャン、フォーム、請求書、領収書 | 文書OCR / Document Intelligence | ページ順、項目、表、モデル版、確認キュー |
| スクリーンショットやグラフへの質問 | Vision model API | プロンプトテンプレート、画像詳細、構造化出力、確認ルール |
| 私的な一括処理 | ローカルOCRまたは承認済みクラウド | 保存境界、アクセス制御、削除、監査ログ |
| アクセシビリティ説明 | 画像理解と編集確認 | ページ文脈、alt text長、長文説明方針 |
「無料で無制限」「精度100%」「デフォルトで安全」といった表示だけで本番設計をしないでください。現在の契約と自分たちのテストセットが必要です。代表的な画像を二十枚ほど用意し、期待する項目、合格条件、許容できないエラーを決めて、同じルートで安定するかを確認します。
チームでは入口を四つに分けると運用しやすくなります。公開低リスク画像、私的なローカル処理、文書項目抽出、画像理解が必要な処理です。それぞれに既定のプロンプト、保存ルール、確認ルールを持たせれば、毎回ツール探しから始めずに済みます。
画像品質も忘れてはいけません。傾き、反射、低解像度、強い圧縮、切れたスクリーンショット、混在言語、手書きの癖は結果を悪化させます。必要なら撮り直し、切り抜き、ページ分割、解像度改善を先に行います。画像文字起こしの品質は、モデルを選ぶ前の準備でかなり決まります。
結果をシステムへ流す場合は、読めない画像を無理に埋めない拒否条件も決めておきます。失敗を明示できる設計のほうが、静かに誤ったデータを作る設計より安全です。
安全に選ぶためのチェックリスト
どの画像文字起こしツールを使う前にも、次を確認してください。
- 画像は公開、低リスク、顧客所有、規制対象、未公開、個人情報入りのどれか。
- 必要な結果はテキスト、表、JSON、alt text、要約、画像への回答のどれか。
- 画像は印刷文字、文書、手書き、グラフ、スクリーンショット、数式、混在内容のどれか。
- アップロード、保存、削除、サポート、課金の責任者は誰か。
- どの項目を元画像と照合するか。
- OCRと画像理解モデルの結果が違う場合、誰が判断するか。
- 同じ画像を同じルートと同じ依頼文で再現できるか。
この問いに答えられないなら、急いで変換しないほうがよいです。最良のツールは一番速いものではなく、ファイルのリスク、画像の複雑さ、下流の使い道に合うものです。
よくある質問
画像の文字起こしと画像生成は同じですか?
同じではありません。画像の文字起こしは、既存の画像からテキスト、項目、表、説明、回答を取り出します。画像生成は、テキストの指示から新しい画像を作ります。
個人情報や社内資料に一番安全な方法は?
ローカルOCR、または組織で承認済みの私的なクラウドOCRや文書処理ルートです。不明な無料サイトへ最初にアップロードするのは避けます。
通常のOCRが画像理解モデルよりよいのはいつですか?
文字がきれいで、正確な転記が主目的のときです。通常のOCRは検証しやすく、規模が大きい場合も扱いやすいです。文脈、表、グラフ、手書き、数式、画面状態が必要なら画像理解モデルを使います。
AIは手書きを読めますか?
読める場合は多いですが、必ず確認が必要です。不確かな語をマークさせ、氏名、金額、日付、医療や法務の意味を元画像で確認します。
スクリーンショット内の表はどう取り出しますか?
Markdown表、CSV、またはJSON行として出力させ、元の見出しを保たせます。その後、見出し、中央の行、最後の行、合計を確認します。表の失敗はスペルより列ずれが多いです。
alt textはOCRですか?
違います。OCRは見える文字を取り出します。alt textは、画像がページで何を伝えるかを説明します。グラフ、装飾画像、商品画像、証拠スクリーンショットでは書き方が変わります。
開発者はどのAPIから始めるべきですか?
仕事で選びます。文字中心の画像と文書にはOCRまたは文書OCR。視覚的な質問、表、グラフ、スクリーンショットの解釈には画像理解モデルAPI。外部に出せないファイルにはローカルOCRまたは承認済みの私的ルートです。
無料の画像文字起こしサイトを業務に使えますか?
公開済みで低リスクの画像なら使えることがあります。業務資料では、運営者、保存、削除、学習利用、権利、サポートを確認してください。無料であることは、安全にアップロードできる証明ではありません。