
Elige Gemini 3 Flash si necesitas mejor rendimiento en coding, agentes, multimodal y tareas cargadas de search, y puedes absorber el riesgo de preview junto con una factura de tokens mas alta. Mantén Gemini 2.5 Flash si pesan mas el coste bajo, la estabilidad GA y un default actual mas simple mientras preparas la migracion.
El marco util aqui es el timing de migracion. Gemini 3 Flash es la lane hacia delante que Google empuja, pero Gemini 2.5 Flash sigue siendo mas barato y sigue siendo racional hasta que la ventana de cierre del 17 de junio de 2026 acerque el riesgo de migracion.
Resumen rápido
- Empieza por Gemini 3 Flash si construyes coding agents, asistentes con herramientas, productos multimodales o flujos donde la calidad extra sí paga el mayor coste.
- Mantén primero Gemini 2.5 Flash si operas pipelines de texto de alto volumen, quieres un default más conservador o dependes de grounding gratuito.
- No retrases la preparación de la migración: Google ya señaló Gemini 3 Flash como camino oficial de sustitución.
La foto oficial se puede resumir así:
| Área | Gemini 3 Flash | Gemini 2.5 Flash | Qué implica |
|---|---|---|---|
| Estado actual | Preview | Stable / GA | 3 Flash es la dirección futura; 2.5 Flash sigue siendo el default más tranquilo |
| Model ID | gemini-3-flash-preview | gemini-2.5-flash | Si fijas IDs, la migración debe ser explícita |
| Fecha de lanzamiento | 17 de diciembre de 2025 | 17 de junio de 2025 | 3 Flash pertenece a la generación más nueva |
| Lifecycle | Sin fecha de apagado anunciada | Apagado el 17 de junio de 2026 | Seguir en 2.5 Flash tiene fecha límite |
| Reemplazo recomendado | N/A | gemini-3-flash-preview | Google ya marcó el destino |
| Standard price | $0.50 input / $3.00 output | $0.30 input / $2.50 output | 3 Flash es más caro |
| Batch price | $0.25 / $1.50 | $0.15 / $1.25 | 2.5 sigue siendo más barato en batch |
| Context / output | 1,048,576 / 65,536 | 1,048,576 / 65,536 | El límite de tokens no decide la comparación |
| Grounding | paid monthly allowances | free Search 500 RPD y free Maps 500 RPD | 2.5 es más cómodo para grounded prototypes baratos |
| Thinking control | thinking_level | thinking_budget | Cambia incluso la forma de ajustar latencia y razonamiento |
| Computer Use | Sí | no aparece como soportado en la Gemini API page | 3 Flash encaja mejor en agentic workflows |
En la práctica, esta tabla sirve más como guía de routing que como veredicto absoluto. Si tienes rutas donde un fallo de modelo cuesta tiempo humano, reintentos o una mala experiencia visible para el usuario, Gemini 3 Flash suele justificar mejor su precio. Si tus rutas principales son resumen barato, extracción, clasificación o support triage a gran escala, la diferencia entre \$0.30 y \$0.50 por input deja de ser un detalle y pasa a ser coste operativo real.
Por eso, la lectura útil a 20 de marzo de 2026 no es “elige un ganador y reemplaza todo”. La lectura útil es “segmenta el tráfico”. Deja que Gemini 3 Flash se quede con el carril quality-first y capability-sensitive, y mantén Gemini 2.5 Flash donde el coste, el grounding gratuito o la estabilidad pesan más. Esa separación reduce bastante el riesgo de llegar a junio con una migración improvisada.
Por qué el launch narrative no basta
La launch post y la página de DeepMind muestran algo real: Gemini 3 Flash no es un simple refresh. En la tabla oficial frente a Gemini 2.5 Flash mejora en puntos que sí se traducen en producto:
- GPQA: 90.4 vs 82.8
- MMMU-Pro: 81.2 vs 66.7
- SWE-bench Verified: 78.0% vs 60.4%
- FACTS: 61.9% vs 50.4%
- MCP Atlas: 57.4% vs 8.8%
Eso explica por qué Google movió gemini-flash-latest a gemini-3-flash-preview en los release notes del 21 de enero de 2026. Para coding, multimodal y agentic tasks, Gemini 3 Flash ya es el carril Flash serio.
Pero en API eso no resuelve todo. Gemini 3 Flash también es:
- más caro
- todavía Preview
- distinto en la forma de controlar thinking
Mientras tanto, Gemini 2.5 Flash sigue siendo:
- más barato
- Stable / GA
- más fácil para grounding gratuito
La pregunta correcta no es “qué modelo es mejor en abstracto”, sino “en qué rutas ese salto de calidad compensa el coste y el riesgo Preview”.
Precio, grounding y fecha de retirada a 20 de marzo de 2026

En la pricing page, el precio estándar actual es:
- Gemini 3 Flash Preview:
\$0.50input y\$3.00output - Gemini 2.5 Flash:
\$0.30input y\$2.50output
En batch:
- Gemini 3 Flash batch:
\$0.25input y\$1.50output - Gemini 2.5 Flash batch:
\$0.15input y\$1.25output
Así que 3 Flash no es “lo mismo pero mejor”. Frente a 2.5 Flash cuesta bastante más. En coding agents quizá lo amortices rápido. En un pipeline barato de extracción o resumen, no necesariamente.
Grounding marca todavía más la diferencia. La pricing page muestra que:
- Gemini 2.5 Flash mantiene free Search grounding hasta 500 RPD y free Maps grounding hasta 500 RPD
- Gemini 3 Flash Preview no presenta el mismo camino free-tier y se apoya en monthly allowances del paid tier
Si tu app depende del grounding integrado de Google, 2.5 Flash sigue siendo más fácil de justificar.
Y luego está el lifecycle. En la deprecations page:
gemini-2.5-flashrelease date: 17 de junio de 2025- shutdown date: 17 de junio de 2026
- recommended replacement:
gemini-3-flash-preview
Esto significa que puedes mantener 2.5 Flash por ahora, pero ya no deberías tratarlo como un default permanente.
Aquí aparece un matiz operativo importante. El ahorro de corto plazo y el riesgo de lifecycle van en direcciones distintas. A corto plazo, 2.5 Flash sigue siendo el camino barato y cómodo. A medio plazo, posponer la preparación de 3 Flash hace que la migración se concentre justo cuando menos margen te queda. Por eso conviene clasificar ya las rutas entre “migrar pronto”, “mantener temporalmente” y “replantear porque quizá ni siquiera deban seguir igual”.
También conviene pensarlo así si tu producto depende mucho de grounding. Que 2.5 Flash siga ofreciendo free Search grounding y free Maps grounding lo vuelve muy atractivo para prototipos o fases tempranas, pero eso no implica que todo grounded workload deba quedarse ahí hasta el último día. La decisión buena es separar qué parte del tráfico necesita de verdad el carril barato y qué parte necesita más calidad o mayor capacidad agentic.
Qué añade Gemini 3 Flash de verdad frente a Gemini 2.5 Flash

Subestimarías la migración si vieras Gemini 3 Flash solo como “un poco mejor”.
Las páginas actuales de Gemini 3 Flash y Vertex AI ponen delante varias diferencias que sí cambian productos:
- Computer Use
- multimodal function responses
- streaming function call arguments
- media resolution control
- thinking_level
Eso importa en coding agents, orchestración con herramientas, productos multimodales y asistentes search-heavy.
Además, no solo cambia la calidad. También cambia la superficie de control. Vertex AI recomienda a quienes venían de thinking_budget: 0 en Gemini 2.5 Flash que empiecen con thinking_level: MINIMAL al migrar a Gemini 3 Flash si quieren un perfil de latencia y coste parecido. Es un detalle muy práctico y muy fácil de pasar por alto.
Ese detalle importa mucho más de lo que parece. Muchas migraciones fallan porque el equipo asume que, si el prompt sigue igual, el comportamiento económico y operativo también será parecido. No es así. Hay que volver a medir tool calls, longitud de respuesta, latencia por percentiles, tasa de reintentos y coste efectivo por tarea completada. El verdadero valor de Gemini 3 Flash no está solo en “ser más listo”, sino en reducir fallos costosos dentro de workflows complejos.
Ahí es donde 3 Flash gana sentido económico. En coding agents, asistentes con varias tools, interfaces multimodales o rutas donde una mala respuesta obliga a reintentar o escalar a humano, pagar más por token puede salir a cuenta. En cambio, en rutas mecánicas y masivas, el salto de calidad puede no compensar el incremento de coste.
Dónde sigue teniendo sentido Gemini 2.5 Flash
Gemini 2.5 Flash sigue siendo razonable en al menos tres escenarios:
1. Workloads muy sensibles al coste
Clasificación, resumen ligero, extracción y routing masivo siguen premiando el menor precio por token.
2. Equipos que quieren mantener un Stable default mientras evalúan
2.5 Flash sigue en Stable / GA, mientras 3 Flash aún es Preview.
3. Prototipos grounded baratos
Si necesitas free Search / Maps grounding para iterar rápido, 2.5 Flash sigue teniendo una ventaja práctica.
En resumen, el mejor argumento a favor de 2.5 Flash no es “es mejor modelo”, sino es más barato, más estable y todavía útil como default temporal o carril grounded de bajo coste.
Además, 2.5 Flash sirve como línea base muy útil mientras evalúas 3 Flash. Tener un carril Stable conocido permite comparar mejor latencia, coste, incidentes y success rate a nivel de workflow. Eso reduce el riesgo de confundir entusiasmo por el modelo nuevo con una mejora real del sistema.
Qué modelo usar para cada workload
| Workload | Elige primero | Por qué |
|---|---|---|
| coding agents / developer tools | Gemini 3 Flash | benchmark y features inclinan claramente la balanza |
| asistentes con muchas tools | Gemini 3 Flash | mejor reasoning, tool use y Computer Use |
| productos search-heavy orientados a calidad | Gemini 3 Flash | el techo de capacidad es mayor |
| summarization / extraction budget-first | Gemini 2.5 Flash | manda el coste |
| grounded prototypes baratos | Gemini 2.5 Flash | mejor historia de grounding gratuito |
| default productivo conservador | Gemini 2.5 Flash por ahora | Stable sigue importando |
| greenfield capability-first | Gemini 3 Flash | es la dirección que Google está empujando |
La regla práctica sería:
- producto nuevo y quality-first: empieza por Gemini 3 Flash
- sistema existente y cost-sensitive: mantén 2.5 Flash y migra por partes
- si puedes enrutar por workload, usa ambos
Si tu stack ya tiene varias clases de tráfico, merece la pena convertir esta decisión en política explícita. Por ejemplo: coding, agentic automation y multimodal support van por Gemini 3 Flash; extraction barata, summarization masiva y grounded FAQ quedan en Gemini 2.5 Flash; los casos dudosos van a un pool de evaluación donde comparas success rate, latency y cost per completed task. Ese enfoque vuelve la comparación mucho más accionable.
Cómo migrar sin romper producción
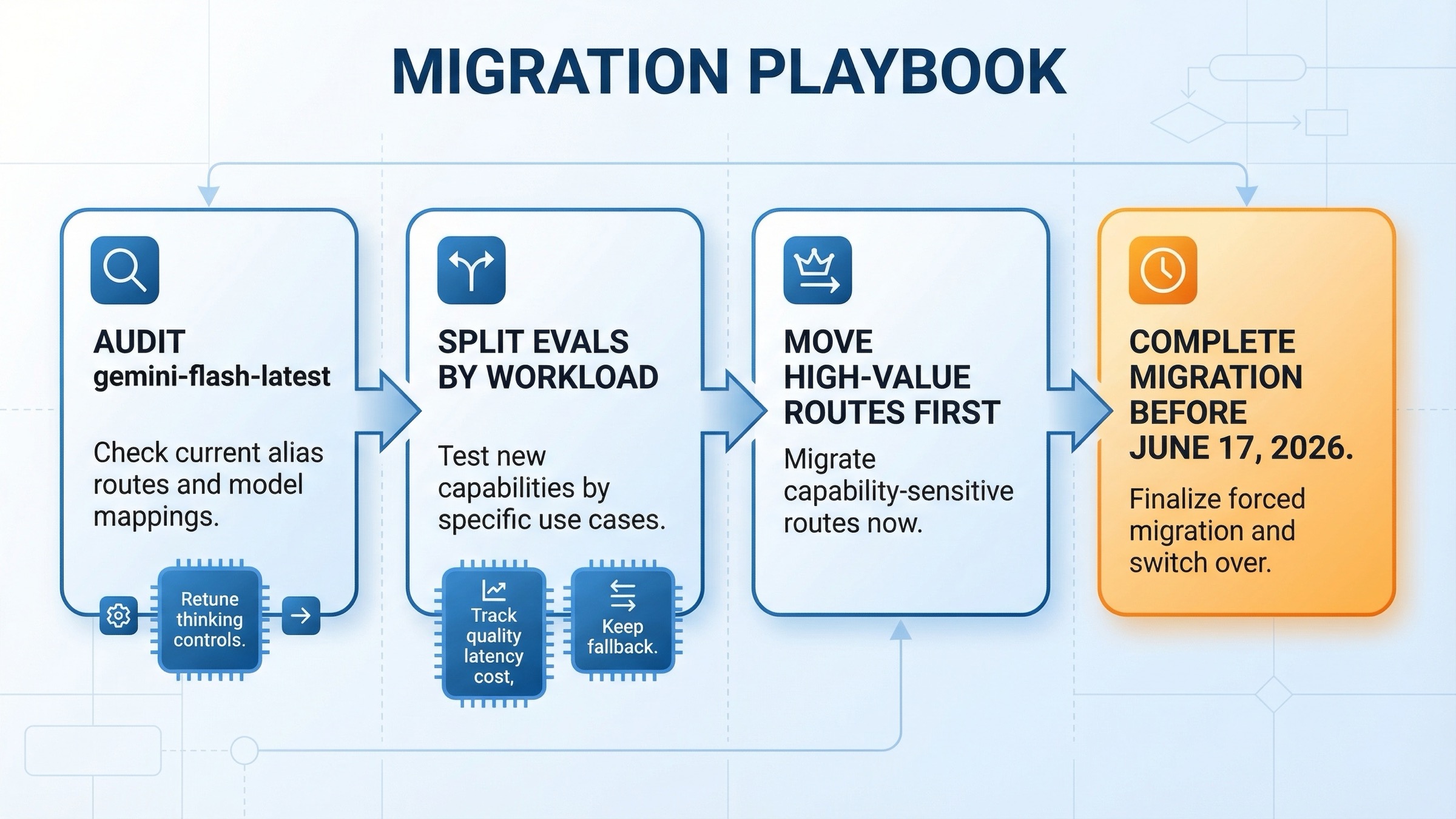
La peor estrategia es un blind swap.
La buena estrategia es staged rollout.
1. Revisa si usas el alias
En release notes figura que gemini-flash-latest ya apunta a gemini-3-flash-preview. Si dependes del alias, parte de la migración puede haberse producido sin que lo estés midiendo bien.
2. Separa las evals por workload
- coding / agentic
- chat / support
- grounded search
- extraction / summarization
- multimodal
3. Reajusta thinking controls
thinking_budget y thinking_level no son equivalentes.
4. Mide quality / latency / cost juntos
Si miras solo uno, te equivocas de criterio.
5. Conserva un fallback hasta completar el cutover
Como 2.5 Flash tiene una fecha visible de retirada y no un apagado inmediato, puedes migrar con disciplina en vez de hacerlo a la fuerza.
Una lectura útil del calendario sería:
- ahora hasta abril de 2026: alias audit y evals por workload
- abril a mayo: mueve primero las rutas donde 3 Flash aporta más valor
- antes del 17 de junio de 2026: cierra el resto de uso pinned a
gemini-2.5-flash
Sumaría una práctica más: define de antemano los criterios de rollback. P95/P99 latency, success rate en rutas con tools, escalaciones manuales, coste por tarea completada o errores en grounded answers son buenos candidatos. Si esos umbrales están escritos antes del cutover, la migración deja de depender de impresiones y pasa a depender de observabilidad.
Y una última recomendación: no hagas todo esto como un simple reemplazo global de model ID. Conviene dejar claro qué prompts, qué tools, qué safety policies y qué datasets de evaluación corresponden a cada ruta. Así, cuando se acerque el 17 de junio de 2026, no estarás buscando usos ocultos en el repositorio, sino cerrando rutas que ya estaban inventariadas.
FAQ
¿Gemini 3 Flash es mejor que Gemini 2.5 Flash?
Sí, si hablamos del capability ceiling. Pero eso no significa que automáticamente sea el mejor default para cualquier sistema en producción.
¿Debo migrar ya?
Debes empezar ya la evaluación y el rollout por fases. No hace falta un full cutover ciego hoy mismo, pero sí dejar de posponer la preparación.
¿Gemini 2.5 Flash todavía merece la pena?
Sí. Sigue siendo más barato, Stable y útil para grounded workloads de bajo coste.
¿Qué detalle de migración se pasa más por alto?
El cambio de thinking_budget a thinking_level. Si tu latencia y tus costes dependían de esa configuración, hay que recalibrarlo.