
Paga Gemini 3.1 Pro Preview cuando el workload sea de verdad duro, sensible a herramientas y muy cargado de ingenieria. Usa por defecto Gemini 3.1 Flash-Lite para trabajo de alto volumen, sensible a latencia y coste, que no necesita razonamiento de nivel Pro.
Esto es primero una decision de routing. Pro no es solo una etiqueta de benchmark mejor, y Flash-Lite no es solo una copia barata. Estan construidos para lanes de produccion distintas, asi que la respuesta correcta depende de que lane necesitas de verdad.
Resumen rápido
Si solo necesitas la decisión práctica, usa esta regla:
- Gemini 3.1 Pro Preview para agentes complejos, software engineering y flujos con herramientas donde un mal resultado sale caro.
- Gemini 3.1 Flash-Lite para traducción, extracción, clasificación, agentes ligeros y tráfico masivo sensible al coste.
- Si tu carga es mixta, no elijas un solo modelo: divide el tráfico.
La foto oficial a 20 de marzo de 2026 es esta:
| Área | Gemini 3.1 Pro Preview | Gemini 3.1 Flash-Lite | Qué significa |
|---|---|---|---|
| Estado actual | Preview | Preview | Ninguno es el GA estable universal |
| Capa gratuita | No | Sí | Flash-Lite es mucho más cómodo para pruebas y staging |
| Precio estándar de entrada | $2.00 / 1M tokens | $0.25 / 1M tokens | Pro cuesta 8 veces más en input |
| Precio estándar de salida | $12.00 / 1M tokens | $1.50 / 1M tokens | También cuesta 8 veces más en output |
| Precio batch | $1.00 in / $6.00 out | Capa gratis, luego $0.125 in / $0.75 out | Flash-Lite es mejor para volumen asíncrono barato |
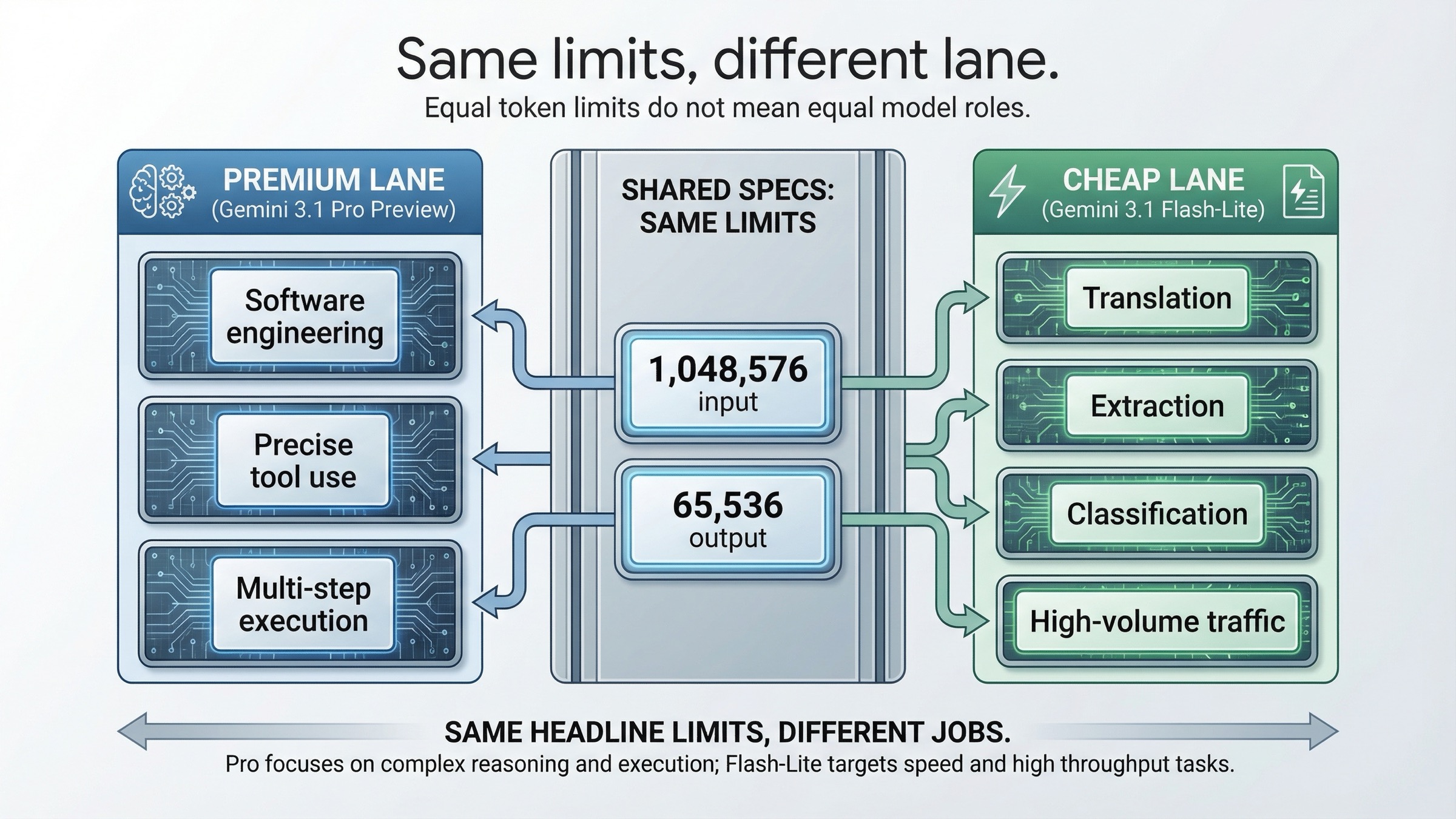
| Límite de entrada | 1,048,576 tokens | 1,048,576 tokens | La ventana de contexto no decide la compra |
| Límite de salida | 65,536 tokens | 65,536 tokens | El tope de output tampoco |
| Techo público de cola batch Tier 1 | 5,000,000 tokens | 10,000,000 tokens | Flash-Lite aguanta mejor colas grandes |
| Mejor uso | Trabajo agente duro, software engineering, tool flows precisos | Traducción, extracción, clasificación, agentes ligeros, gran volumen | Ese es el reparto real |
Esta lectura sale de las páginas oficiales de pricing, Gemini 3.1 Pro Preview, Gemini 3.1 Flash-Lite Preview, la página pública de rate limits y las model cards de DeepMind para Gemini 3.1 Pro y Gemini 3.1 Flash-Lite.
Por qué esto no va de contexto, sino de enrutamiento
El error más común aquí es pensar que Pro debe ser el predeterminado solo porque es el modelo premium, o pensar que Flash-Lite es poco más que una versión recortada del mismo producto. Las páginas oficiales no apoyan ninguna de esas simplificaciones.
Empecemos por lo que sí es igual. En las dos páginas oficiales de modelo aparecen 1,048,576 input tokens y 65,536 output tokens. Eso significa que no estás pagando Pro por una ventana de contexto mayor ni por un output más largo. Justamente por eso esta comparación no debe plantearse como una guerra de límites.
La diferencia real es otra: qué compras con el modelo más caro y qué dejas de comprar con el más barato.
La página de Gemini 3.1 Pro Preview habla de mejor thinking, mejor eficiencia de tokens, mejor consistencia factual, mejor comportamiento para software engineering, mejor uso de herramientas y ejecución multietapa más fiable. Eso es lenguaje de carril premium.
La página de Gemini 3.1 Flash-Lite Preview enfatiza otra cosa: tareas ligeras de alta frecuencia, traducción, extracción simple, clasificación, latencia muy baja y agentes de gran volumen. No es "el mismo Pro pero más pequeño"; es otro objetivo de optimización.
Por eso las preguntas útiles son:
- ¿Qué solicitudes sí necesitan un razonamiento más fuerte y un comportamiento más fiable con herramientas?
- ¿Qué solicitudes son trabajo de carril barato y no deberían pagar tarifa Pro?
- ¿Tu carga es homogénea o conviene dejar Flash-Lite como base y subir solo los casos duros a Pro?
Ese es el marco que vuelve útil toda la evidencia oficial.
Precio, economía batch y realidad pública de límites a 20 de marzo de 2026

El precio es el punto donde la comparación deja de ser teórica.
En la página oficial de pricing, Gemini 3.1 Pro Preview no tiene capa gratuita. Hasta 200k prompt tokens, Google publica $2.00 por 1M de input y $12.00 por 1M de output. Por encima de 200k, la tarifa sube a $4.00 input y $18.00 output. Batch reduce el coste, pero incluso así sigue siendo $1.00 input y $6.00 output.
Flash-Lite está en otro universo. Mantiene free tier, y su precio pagado es solo $0.25 input y $1.50 output. En batch baja todavía más: $0.125 input y $0.75 output.
Eso significa una diferencia de 8x tanto en input como en output. Por eso Pro tiene que justificar su propio precio. Si la mejora de calidad es pequeña, casi nunca compensa usarlo como valor por defecto. Si la mejora de calidad evita muchos fallos de herramienta, reintentos caros o revisión humana, entonces sí puede merecerlo. Pero tiene que demostrarlo.
La página pública de rate limits refuerza la misma lectura. Google ya no ofrece una tabla pública fija de RPM y TPM para todos los modelos, sino que remite a AI Studio para ver los valores activos. Eso significa que no conviene convertir un artículo en una tabla de RPM supuestamente eterna. Pero sí deja una cifra muy útil: el Tier 1 Batch enqueued token limit.
En este momento, la página pública muestra:
- Gemini 3.1 Pro Preview: 5,000,000
- Gemini 3.1 Flash-Lite: 10,000,000
Para muchos sistemas reales, esa diferencia importa más de lo que parece, porque gran parte del tráfico no es chat interactivo, sino trabajo de fondo:
- traducción por lotes
- extracción de documentos
- clasificación y etiquetado
- resúmenes masivos
- enrutamiento asíncrono
En ese contexto, Flash-Lite no solo es más barato; también es más cómodo para volumen en cola.
Grounding tampoco le da a Pro una ventaja decisiva en coste. La página de precios muestra 5,000 grounding prompts gratis al mes para ambos modelos en uso pagado, y luego $14 por 1,000 queries para Search o Maps. Así que el cuadro económico sigue apuntando en la misma dirección.
En pocas palabras: si la tarea pertenece al carril barato, casi nunca tiene sentido dejarla por defecto en Pro.
Cuándo Gemini 3.1 Pro Preview sí paga su sobrecoste
Sería un error convertir este artículo en "la opción barata siempre gana". Hay trabajos donde Pro sí se amortiza.
La página de Gemini 3.1 Pro Preview destaca software engineering, uso preciso de herramientas y ejecución multietapa fiable. La model card de Gemini 3.1 Pro, publicada el 19 de febrero de 2026, refuerza esa posición con una historia de benchmark más fuerte en tareas difíciles como Humanity's Last Exam, GPQA Diamond, Terminal-Bench 2.0, SWE-Bench Verified y APEX-Agents.
Esos benchmark no significan que tu sistema vaya a mejorar exactamente en la misma proporción. Pero sí dan una señal útil: Pro es el carril apropiado cuando la calidad cambia de verdad la economía del flujo:
- planes de agentes de varios pasos
- coding agents con muchas herramientas
- flujos donde una mala decisión de herramienta arrastra varios errores
- tareas de reasoning complejas donde repetir barato sigue saliendo caro
- trabajo de software engineering donde un mejor primer borrador ahorra tiempo real del equipo
Hay además una señal práctica de workflow: la documentación oficial expone una línea gemini-3.1-pro-preview-customtools para escenarios mixtos de bash y herramientas personalizadas. Eso no obliga a mover todos los agentes a Pro, pero sí muestra dónde coloca Google los flujos más pesados.
Incluso la fricción de comunidad va en la misma dirección. Un hilo de Reddit como "I had to switch to 3.1 Pro Preview Custom Tools for my Agent" no es una especificación oficial, pero sí ilustra bien qué clase de problema hay detrás de esta búsqueda: gente intentando que agentes reales funcionen mejor con herramientas reales.
La forma correcta de pensar Pro es esta:
Usa Pro cuando el coste de una mala respuesta sea bastante mayor que el coste de los tokens.
Si eso no es verdad para tu tarea, Pro rara vez debería ser el predeterminado.
Por qué Gemini 3.1 Flash-Lite debería seguir siendo tu carril barato por defecto
Flash-Lite se infravalora con facilidad porque muchas comparativas asumen que el modelo más capaz debe ser el default. Pero la documentación oficial actual de Google empuja en otra dirección: Flash-Lite es el carril económico para trabajo real a escala.
La página de Gemini 3.1 Flash-Lite Preview y la model card de Gemini 3.1 Flash-Lite repiten prácticamente el mismo conjunto de casos:
- traducción
- clasificación
- extracción simple
- baja latencia
- llamadas muy frecuentes
- grandes colas asíncronas
- agentes ligeros
Eso cubre una cantidad enorme de tráfico real.
Si tu sistema procesa sobre todo entradas claras y salidas relativamente controladas, Flash-Lite no es solo "más barato". En muchos escenarios es el modelo correcto, porque no pagas el techo premium de Pro donde no hace falta. Para extracción, etiquetado, traducción masiva, resúmenes repetitivos y pipelines de routing, Pro a menudo no es "mejor", sino simplemente "más caro de lo necesario".
La capa gratuita refuerza todavía más esa conclusión. Para muchos equipos, free tier no sirve solo para ahorrar unos dólares, sino para mantener una pista barata de validación:
- pruebas de prompts
- smoke tests en staging
- validación de reglas de enrutamiento
- regresiones de bajo volumen
Desde el punto de vista operativo, eso es valioso. Un modelo barato con capa gratuita permite mantener hábitos sanos de validación; un carril premium de pago tiene más sentido cuando ya has demostrado el ROI.
Por eso Flash-Lite no debería verse como un plan B, sino como el carril barato por defecto para el tipo de trabajo adecuado.
¿Reemplazar, mantener o dividir el tráfico?
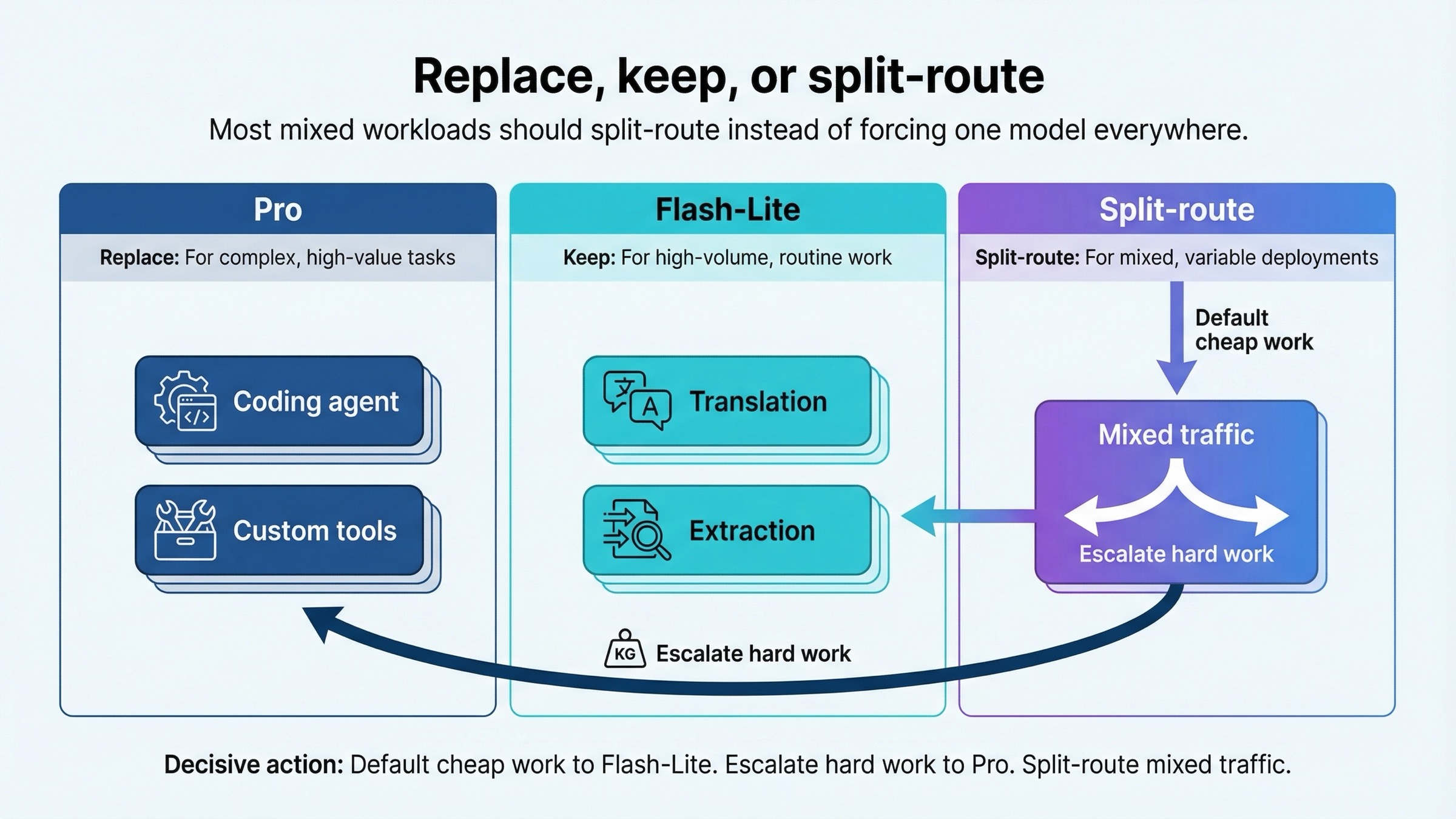
Para la mayoría de equipos serios, la respuesta sensata no es un extremo.
Si envías todo a Pro, casi seguro pagarás demasiado por trabajo rutinario. Si mandas todo a Flash-Lite, acabarás notando la pérdida justo en las tareas donde el error más cuesta. Por eso, para cargas mixtas, la salida más defendible es el split-routing.
Una regla práctica sería esta:
| Carga | Mejor predeterminado | Motivo |
|---|---|---|
| Coding agent con herramientas | Gemini 3.1 Pro Preview | Aquí pesan más la calidad y la ejecución multietapa |
| Orquestación con herramientas personalizadas | Gemini 3.1 Pro Preview | Pro tiene un posicionamiento más claro en tool workflows |
| Traducción masiva | Gemini 3.1 Flash-Lite | Mucho más barato y alineado con el caso de uso oficial |
| Extracción y etiquetado estructurado | Gemini 3.1 Flash-Lite | Trabajo típico del carril barato |
| Grandes colas batch | Gemini 3.1 Flash-Lite | Mejor economía batch y mayor techo de cola público |
| Tráfico mixto | Split-route | Flash-Lite como base y Pro como carril de escalado |
En la práctica suele funcionar así:
- Arranca el tráfico masivo nuevo sobre Flash-Lite.
- Prueba Pro solo sobre los segmentos donde el fallo es caro: coding difícil, flujos multietapa, herramientas complejas.
- Si Pro demuestra un ahorro real, abre un carril premium solo para esas solicitudes.
Eso es mucho más útil que la frase vacía "Pro para calidad, Lite para precio". La regla operativa correcta es:
Deja el trabajo barato y rutinario en Flash-Lite. Escala a Pro solo el trabajo difícil y caro. Si la carga es mixta, divide el tráfico.
Si quieres ver cómo encaja Flash-Lite frente a otra opción rápida más potente, continúa con nuestra comparativa Gemini 3.1 Flash-Lite vs Gemini 3 Flash. Si quieres ubicar Pro frente a una línea premium más estable, revisa Gemini 3.1 Pro vs Gemini 2.5 Pro.
FAQ
¿Gemini 3.1 Pro Preview es siempre mejor que Gemini 3.1 Flash-Lite?
Solo en tareas realmente difíciles. Para mucho trabajo barato y repetitivo, Flash-Lite es el default más razonable.
¿Cuál es más barato?
Flash-Lite. A 20 de marzo de 2026, el precio estándar de Pro es $2.00 input / $12.00 output, mientras que Flash-Lite cuesta $0.25 input / $1.50 output.
¿Tienen los mismos límites de tokens?
Sí. Las páginas oficiales de ambos modelos muestran 1,048,576 input tokens y 65,536 output tokens. Por eso esta comparación no va de tamaño de ventana.
¿Cuál conviene para coding agents?
Si el agente es complejo, usa herramientas y sale caro revisarlo, empieza con Pro. Si es un flujo ligero y repetitivo, Flash-Lite puede ser suficiente como baseline.
¿Cuál conviene para traducción o extracción a gran escala?
Flash-Lite. Su precio, su posición oficial y su economía batch lo convierten en la opción natural para ese trabajo.