
Si Claude API devuelve HTTP 500 y el cuerpo marca api_error, actúa como si la solicitud hubiera llegado a Claude y hubiera fallado dentro del servicio. Antes de cambiar la key, editar el prompt, mover el tráfico a otra ruta o repetir el trabajo, conserva el request_id o el header request-id, la hora del fallo, el model, el endpoint, el dueño de la autenticación, el SDK o gateway usado, la base URL, la red y la forma de la solicitud.
El 19 de mayo de 2026, Claude Status aparecía operativo, con incidentes recientes ya resueltos de errores elevados. Esa comprobación fechada solo reduce una rama: no prueba que tu model exacto, cuenta, región, gateway o carga estén sanos. Úsala para decidir si esperas o proteges tráfico, pero no la uses para borrar la evidencia del mismo camino.
Trabaja con esta tabla antes de tocar variables.
| Señal visible | Primera acción | Verifica | Regla de parada |
|---|---|---|---|
HTTP 500 con rama interna de servidor | Guarda request_id, hora, model, endpoint y ruta; revisa Claude Status | El mismo camino se recupera o repite la misma rama | Detén el loop tras un presupuesto pequeño de reintentos |
529 overloaded_error | Trátalo como presión de capacidad; baja concurrencia y retry pressure | La rama desaparece tras backoff y menor carga | No lo depures como validación local |
429 rate_limit_error | Revisa cuota, ritmo, token volume y concurrencia | El flujo mejora con pacing o ajuste de límites | No cambies keys como arreglo por defecto |
504 timeout_error o petición larga | Acorta, usa streaming, batches o timeouts conscientes | Una petición menor o streaming termina en la misma cuenta | No lo mezcles con un 500 limpio |
| DNS, TLS, proxy, firewall, timeout del SDK antes de respuesta | Prueba base URL, proxy, red y SDK timeout por separado | Una petición pequeña alcanza la API y recibe respuesta clara | No apliques reglas de retry de 500 a un fallo de conexión |
| 500 limpio repetido en el mismo camino | Prepara un paquete con request IDs, timestamp, timeline y request shape anonimizado | Soporte o plataforma puede correlacionar el evento | No envíes secrets, prompts completos, auth headers ni datos privados |
Cuando una rama da evidencia suficiente, deja de mover piezas. Si el mismo camino repite 500 después del presupuesto pequeño, escalar con pruebas vale más que cambiar prompt, model, provider y gateway a la vez.
Qué significa un 500 api_error limpio
La documentación de errores de Anthropic asigna HTTP 500 a api_error. Esa es la rama oficial: el servicio devolvió un fallo interno inesperado. No es, por defecto, una mala key, un problema de billing, una validación de JSON, una cuota agotada o una red corporativa bloqueando la conexión.
La respuesta puede incluir error.type, error.message y un request_id; las respuestas de API también pueden exponer el header request-id. Por eso el primer hábito operativo no es "probemos otra vez", sino "dejemos trazabilidad". Sin esos identificadores, el proveedor, un gateway o tu plataforma interna tienen muchas menos probabilidades de encontrar el evento exacto.
Un 500 limpio tampoco significa que todos los fallos sean iguales. Puede ser un incidente transitorio, un camino concreto de un model, una dependencia interna, un wrapper de gateway, una región o una combinación de workload y endpoint. La pregunta útil no es "Claude está caído o mi código está mal". La pregunta útil es si el mismo model, endpoint, auth owner, SDK o gateway, base URL, red y request shape reproducen la rama.
No empieces rotando credenciales. Una key inválida debería producir una rama de autenticación o permisos. Tampoco empieces reescribiendo el prompt. Un payload mal formado debería aparecer como 4xx. El tamaño del request, los attachments, tool calls o modo streaming pueden importar, pero son revisiones de segunda capa después de conservar estado, identificadores y prueba del mismo camino.
Claude Code merece separarse. La documentación de Claude Code sobre errores explica que Claude Code puede mostrar cuerpos 5xx de la API. Si la terminal enseña API Error: 500, la superficie visible es Claude Code, pero la rama subyacente puede seguir siendo la respuesta de API. Auth local, MCP, permisos de tools y versión del CLI son capas adicionales, no la conclusión automática.
Separa la rama antes de arreglarla
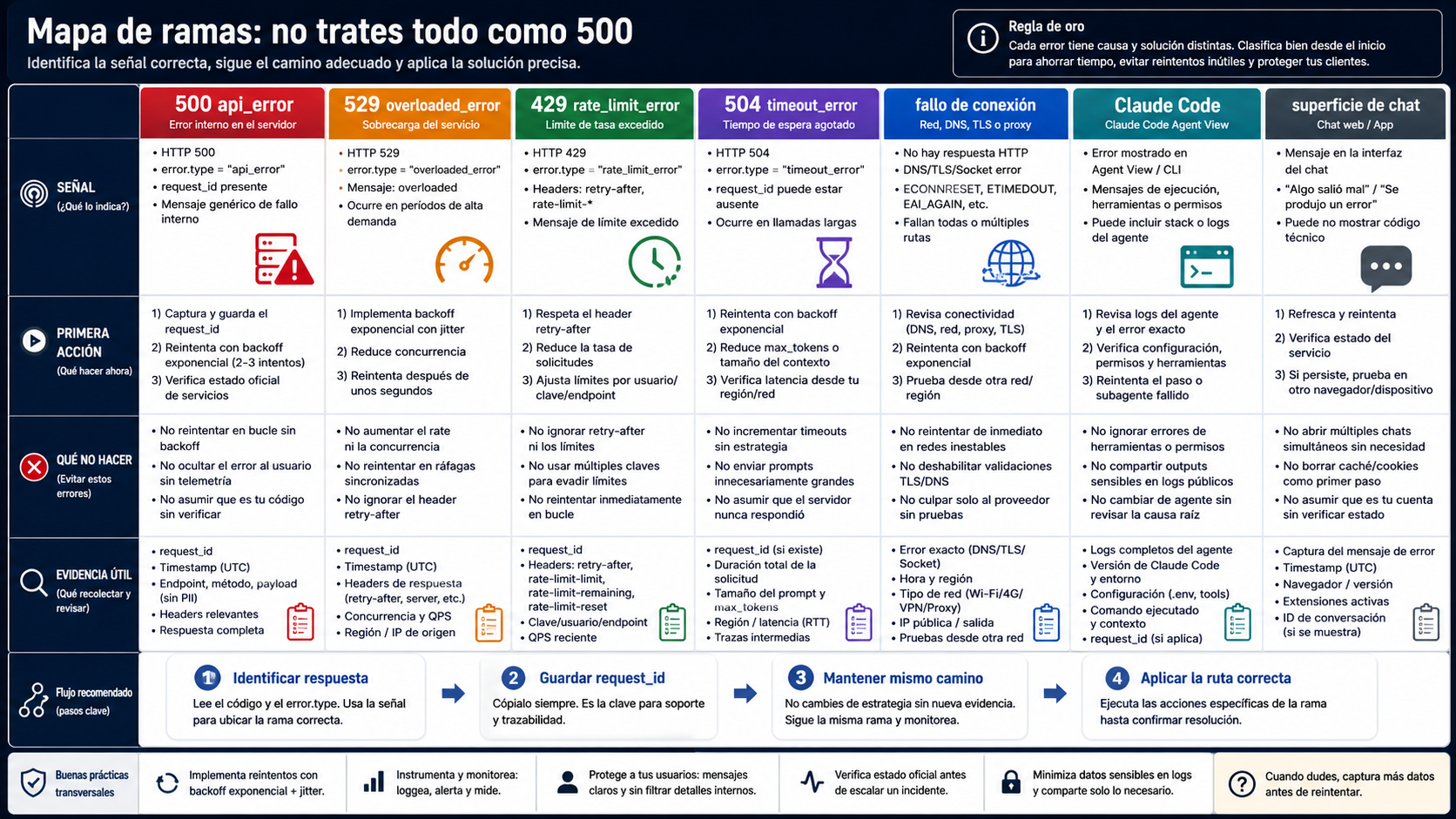
La forma más rápida de perder tiempo es aplicar un arreglo correcto a la rama equivocada. 500 api_error, 529 overloaded_error, 429 rate_limit_error, 504 timeout_error y un fallo de conexión pueden detener el mismo producto, pero no piden la misma respuesta.
Usa la rama 500 api_error cuando tienes una respuesta HTTP devuelta por Claude y el body o la excepción del SDK identifica el fallo interno. La evidencia importante es status, request ID, model, endpoint y ruta. La primera recuperación es revisar estado y reintentar poco, no hacer matemáticas de cuota ni editar el prompt.
Usa 529 overloaded_error cuando la capacidad está presionada. Ahí el problema principal es no crear una tormenta de reintentos. Reduce concurrencia, espera y cambia el ritmo. Si el body ya dice 529, la ruta más precisa es Claude 529 Overloaded Error, porque la decisión deja de ser interna 500 y pasa a ser capacidad.
Usa 429 rate_limit_error cuando la cuenta u organización está siendo limitada. Revisa límites, volumen de tokens, batching, concurrencia y headers de pacing. Si tratas un 429 como 500, puedes esperar un incidente que no existe; si tratas un 500 como 429, puedes perder el request_id que permitiría correlacionar el fallo.
Usa 504 timeout_error cuando la operación no termina a tiempo. Peticiones largas pueden necesitar streaming, Message Batches, división de trabajo o timeouts más explícitos. Si no recibiste un 500 limpio, no diagnostiques el problema como fallo interno solo porque la experiencia humana sea "Claude no respondió".
Usa la rama de conexión cuando no hay respuesta de API. DNS, TLS, proxy, firewall, VPN, base URL incorrecta y timeout local pueden fallar antes de que Anthropic devuelva api_error. Una petición pequeña conocida, otra red y una base URL limpia valen más en esa rama que repetir la operación grande.
Ejecuta un bucle corto de recuperación
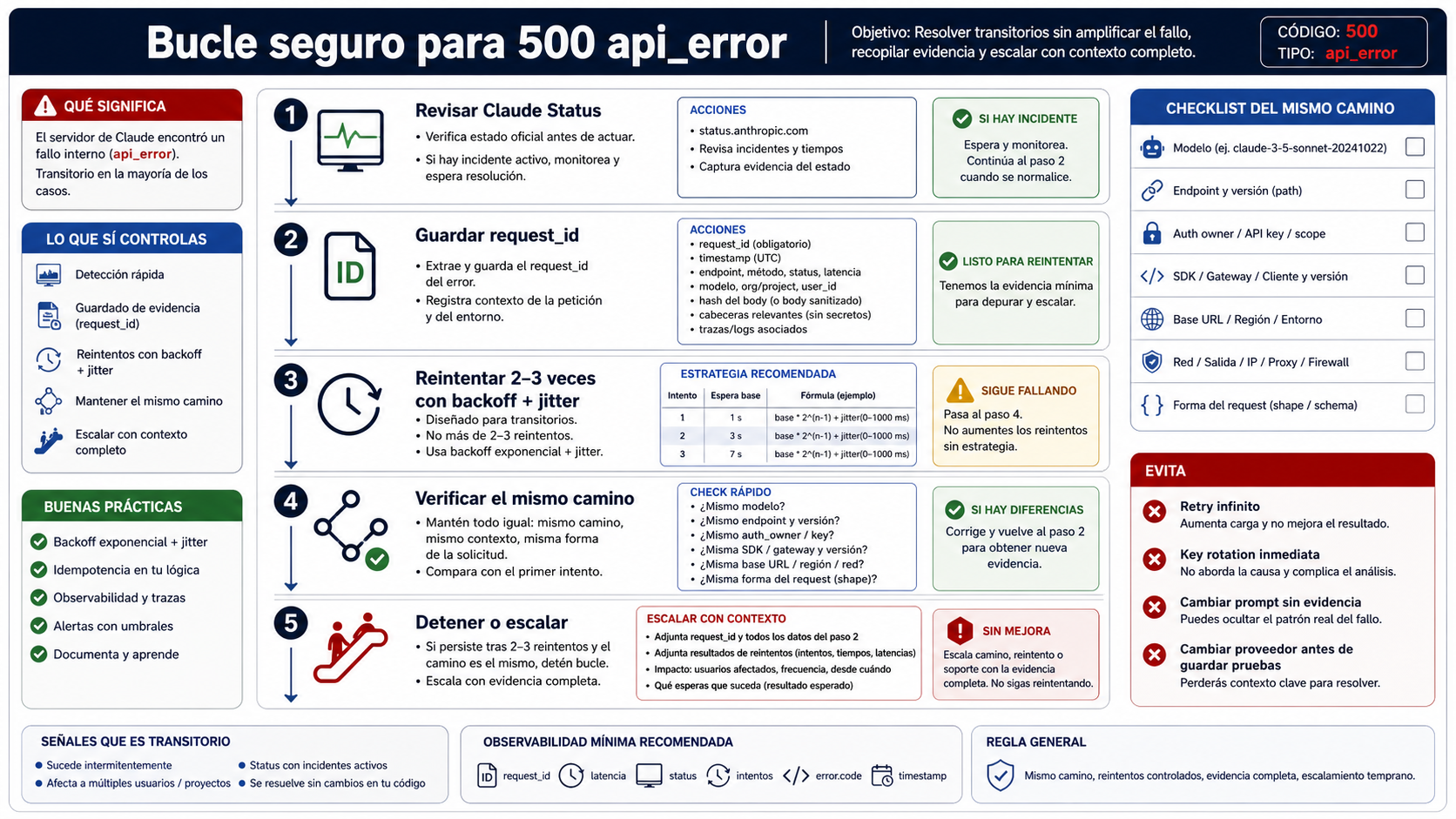
El bucle operativo debe ser corto: estado, evidencia, reintento limitado, mismo camino, parada o escalado. Cada paso evita un error común.
Primero, revisa Claude Status y anota la hora. Si hay un incidente activo, reduce presión, protege usuarios y evita repetir tráfico que no aporta información. Si el estado aparece limpio, no concluyas que todo es local; concluye que necesitas mejor evidencia del mismo camino.
Segundo, guarda identificadores. En API directa, captura el request_id del body si aparece y el header request-id cuando esté disponible. En SDKs, añade clase de excepción, HTTP status, model, endpoint, base URL, SDK version, responsable de la ruta y correlation ID interno. En Claude Code o gateway, conserva raw body, trace ID del gateway y contexto del comando.
Tercero, reintenta con presupuesto pequeño. Dos o tres intentos a nivel de aplicación pueden ser demasiado si el SDK ya reintentó por dentro. Usa backoff y jitter, limita el tiempo total y detén la cadena si el mismo 500 limpio se repite.
Cuarto, verifica el mismo camino. Mismo camino significa mismo model, endpoint, auth owner, SDK o gateway, base URL, red, headers sin secrets y request shape. Si cambias tres variables y el request siguiente funciona, no sabes si Claude se recuperó, si cambió la ruta o si el payload dejó de activar el mismo comportamiento.
Quinto, decide entre registrar, pausar o escalar. Si un reintento limitado funciona y la operación es idempotente, guarda el evento y monitoriza. Si se repite, deja de modificar la solicitud y prepara el paquete de evidencia.
tsasync function callClaudeWith500Budget(runClaude: () => Promise<unknown>) { const maxAttempts = 3; const baseDelayMs = 800; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await runClaude(); } catch (error: any) { const status = error?.status || error?.statusCode; const type = error?.error?.type || error?.type; if (status !== 500 || type !== "api_error") { throw error; } recordClaude500Evidence({ attempt, requestId: error?.request_id || error?.headers?.["request-id"], status, type, }); if (attempt === maxAttempts) { throw error; } const jitter = Math.floor(Math.random() * 400); await sleep(baseDelayMs * 2 ** (attempt - 1) + jitter); } } }
Lo importante no es copiar ese delay exacto. Lo importante es que el handler no trate todas las excepciones como retryable, registre evidencia antes de dormir y se detenga tras un presupuesto definido.
Haz seguro el reintento antes de repetir trabajo
Un retry solo es seguro si repetir la operación es seguro. Clasificación, resumen y análisis read-only suelen tolerar reintentos. Flujos que escriben registros, envían mensajes, disparan pagos, actualizan tickets, crean archivos o ejecutan tools necesitan protección de idempotencia antes de repetir.
Separa "falló la llamada al model" de "ya ocurrió el side effect". Si escribes en base de datos antes de llamar a Claude, fija un job ID y deduplica en replay. Si una tool puede enviar un email o hacer una compra, no repitas toda la cadena porque el último paso devolvió 500. Guarda estado intermedio y decide qué subpaso se puede repetir.
Una política legible tiene cuatro números: máximo de intentos, delay inicial, forma del backoff y tiempo máximo. Un fallo transitorio puede recuperarse dentro de ese presupuesto; uno persistente debe activar una regla de parada. Sin esos números, "usa backoff" termina siendo una frase que cada equipo implementa de forma distinta.
En producto, el usuario también necesita un estado claro. Si el request es no crítico, puedes encolar y reintentar más tarde. Si es interactivo, muestra una degradación honesta: el trabajo no se perdió, el equipo ya tiene un identificador y el resultado se reintentará o se notificará. Esa experiencia es mejor que un spinner infinito que dispara solicitudes sin control.
Distingue API directa, Claude Code y gateway
La propiedad de la ruta es donde muchos incidentes se vuelven confusos. Una llamada directa a Anthropic, una sesión de Claude Code, un test de Workbench, un gateway hospedado, un proxy corporativo y un servicio interno pueden acabar en la misma sensación: "Claude falló". Operativamente no son el mismo camino.
En API directa, Anthropic posee la respuesta del servicio y tu equipo posee construcción del request, logs, retry policy e idempotencia. En Claude Code, la terminal puede mostrar la respuesta cruda, pero auth local, MCP servers, permisos de tools y actualizaciones del CLI pueden sumar su propia capa. En un gateway, base URL, selección de proveedor, handoff de credenciales, logging y reintentos previos pueden haber ocurrido antes de llegar a Anthropic.
Por eso la verificación del mismo camino incluye quién controla cada capa. Si el request directo falla con 500 limpio pero el mismo payload funciona a través de un gateway, la evidencia es útil, pero no demuestra por sí sola que Anthropic esté sano o roto. Demuestra que una ruta tuvo un resultado diferente. Guarda el request ID original, el trace ID del gateway, la base URL y la hora por separado.
No cambies de proveedor como primera reacción. Un fallback puede ser necesario para continuidad de negocio, pero si lo activas antes de conservar la falla original, pierdes el hilo diagnóstico. Primero guarda el evento; después decide si el producto necesita servir por otra ruta mientras investigas.
Prepara el paquete de escalado
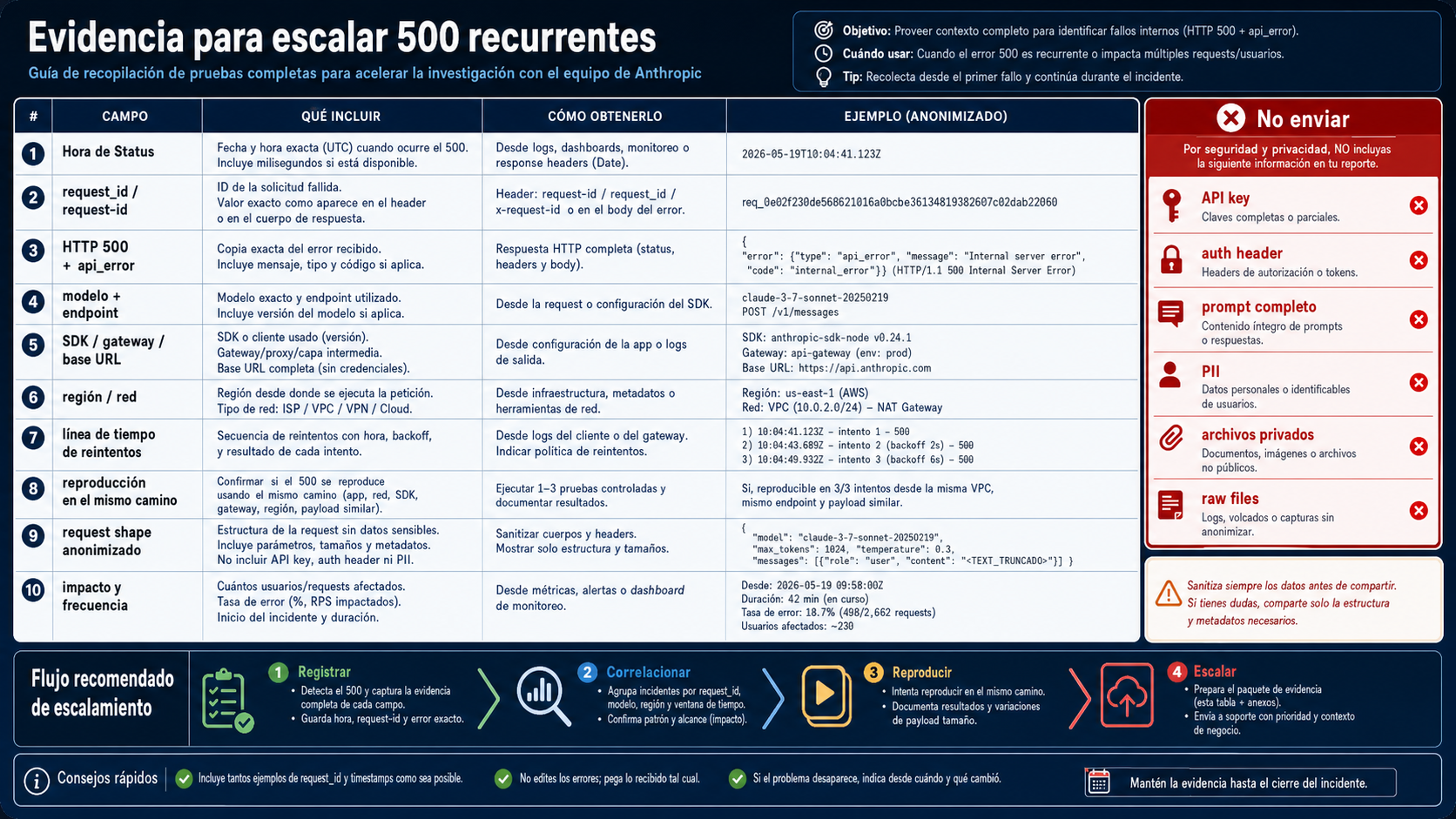
Escalar funciona mejor cuando el paquete permite correlacionar sin exponer secretos. No envíes API keys, bearer tokens, auth headers, prompts privados completos, PII, archivos de clientes, raw files ni datos confidenciales. Envía metadata, forma anonimizada e identificadores.
| Campo | Por qué importa |
|---|---|
| Hora de Claude Status | Muestra si el fallo coincide con un incidente público o con una ventana limpia |
request_id o request-id | Permite rastrear la respuesta concreta |
HTTP status y error.type | Confirma 500 api_error frente a 429, 529, 504 o conexión |
| Model y endpoint | Separa un problema de model de una ruta o cuenta |
| SDK, gateway, base URL y región | Identifica la capa que pudo envolver o enrutar el request |
| Timeline de reintentos | Muestra si persistió tras backoff limitado |
| Reproducción del mismo camino | Prueba que no cambiaste variables |
| Request shape anonimizado | Enseña tamaño, tools, streaming y attachments sin filtrar datos |
| Impacto y frecuencia | Ayuda a priorizar ruido puntual frente a degradación real |
Si ocurre en Claude Code, añade versión, comando, si apareció el cuerpo 5xx en terminal, si el mismo trabajo falla en Workbench o API directa y si hay síntomas de auth o login. Si ocurre en gateway o servicio interno, incluye tanto el trace ID del gateway como cualquier request ID de Anthropic expuesto por la ruta.
Un timeline corto suele ser mejor que una explicación larga: primera hora del fallo, hora de status, intentos, reproducción, impacto actual y cambios recientes. El receptor debe poder buscar el evento sin leer una historia extensa.
Trata los 500 recurrentes como evento operativo
Los equipos que dependen de Claude no deberían inventar su política de 500 durante un incidente. El primer control es logging estructurado. Cada fallo debe conservar status, type, request ID, model, endpoint, ruta, elapsed time, attempt number y correlation ID propio.
El segundo control es un circuit breaker. Si los 500 limpios suben por encima de un umbral, pausa trabajos no críticos de alto volumen, protege interfaces con un mensaje degradado y reduce retry pressure. La meta no es abandonar Claude tras un fallo interno; la meta es no convertir un problema del proveedor en una tormenta de tráfico propia.
El tercer control es diseño idempotente. Encola trabajos que pueden esperar, deduplica los que se pueden repetir y marca acciones no repetibles antes o después de la llamada al model. Si el model call es solo un paso dentro de un flujo mayor, no repitas todo el flujo automáticamente.
El cuarto control es aislamiento de rutas. API directa, gateway, Claude Code, producto de chat e internal service deben verse en dashboards separados. Una línea verde en una ruta no debe tapar una línea roja en otra.
El quinto control es propietario de escalado. Decide quién revisa Claude Status, quién abre ticket, quién puede bajar concurrencia, quién puede activar fallback y quién comunica degradación a usuarios. Lo peor es que varias personas cambien variables mientras nadie conserva los primeros request IDs.
Preguntas frecuentes
¿Un 500 de Claude API significa que mi prompt está mal?
Normalmente no. HTTP 500 con api_error es la rama interna de servidor. Prompts inválidos, JSON mal formado, problemas de auth o permisos deberían aparecer como ramas distintas. Guarda evidencia primero; revisa tamaño del prompt, tools o attachments después.
¿Debo rotar la API key?
No como arreglo por defecto. La rotación pertenece a ramas de autenticación, permisos o exposición de secretos. En un 500 limpio, cambiar key añade una variable y puede borrar evidencia útil. Guarda request ID y verifica el mismo camino antes de tocar credenciales.
¿Cuántos reintentos son seguros?
Usa un presupuesto pequeño, no un loop indefinido. Un punto de partida razonable son dos o tres intentos de aplicación con backoff y jitter, ajustados si el SDK ya reintentó. Detente antes en flujos no idempotentes y escala si el mismo camino repite 500.
¿Claude Status en verde prueba que el fallo es local?
No. Un estado verde es una señal fechada, no una prueba de que tu model, cuenta, región, gateway o workload estén sanos. Significa que debes conservar evidencia del mismo camino y evitar culpar automáticamente a un incidente público.
¿500 api_error es lo mismo que 529 overloaded_error?
No. Ambos pueden parecer fallos del proveedor, pero son ramas distintas. 500 api_error es una falla interna inesperada. 529 overloaded_error apunta a capacidad o sobrecarga. Si la rama cambia a 529, reduce presión y sigue el camino de overload.
¿Claude Code puede mostrar el mismo fallo?
Sí. Claude Code puede mostrar cuerpos 5xx de la API. Guarda raw body, request ID si existe, versión del CLI, comando y ruta. Después separa síntomas locales de Claude Code del response subyacente.
¿Cuándo conviene escalar?
Escala cuando el mismo camino repite 500 tras el presupuesto pequeño, o cuando el impacto al usuario es material. Incluye timestamp de status, request IDs, model, endpoint, ruta, timeline, request shape anonimizado e impacto. No incluyas secrets ni prompts privados completos.
¿Cambio de provider si aparece 500?
Solo después de conservar evidencia del fallo original. Un fallback puede proteger producción, pero no sustituye request IDs, status check y reproducción del mismo camino. Trátalo como política de continuidad, no como diagnóstico.