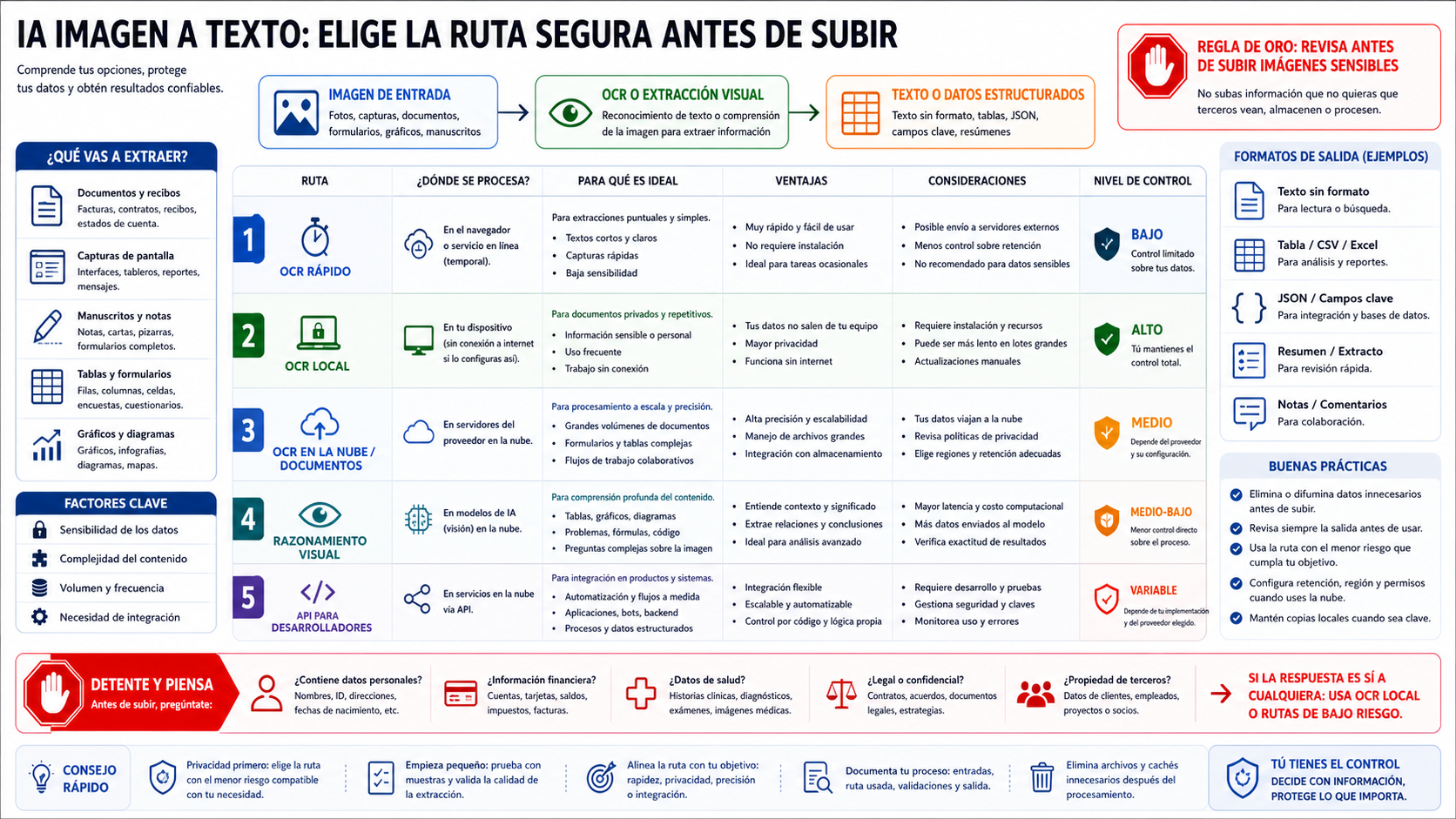
Si quieres convertir una imagen a texto, no empieces por el primer cuadro de subida gratuito. Empieza por una pregunta más importante: ¿puedo subir este archivo a ese servicio? Una captura pública, un menú, una etiqueta o un escaneo de bajo riesgo pueden pasar por OCR rápido. Un contrato, una factura de cliente, un formulario médico, un estado financiero, un documento de identidad o una pantalla interna debería pasar primero por OCR local o por una ruta privada verificada.
| Si tu archivo o tarea se parece a esto | Empieza por esta ruta | Por qué |
|---|---|---|
| Captura pública, menú, etiqueta o escaneo corto | OCR rápido | El riesgo es bajo y normalmente necesitas texto plano. |
| Material de cliente, legal, médico, financiero, interno o no publicado | OCR local o ruta privada verificada | La frontera de subida importa más que la comodidad. |
| Facturas, recibos, formularios, páginas escaneadas, lotes | OCR documental o OCR en la nube | Importan campos, tablas, orden de páginas y repetibilidad. |
| Escritura manual, tablas, gráficos, ecuaciones, UI densa | Modelo visual | Hay que interpretar estructura y contexto, no solo caracteres. |
| Producto, automatización o flujo backend | API | Necesitas autenticación, logs, reintentos, coste, datos y esquema de salida explícitos. |
El formato de salida también debe decidirse antes de subir: texto plano, tabla Markdown, CSV, JSON, LaTeX, alt text o una respuesta corta sobre lo que muestra la imagen. Trata la primera extracción como un borrador. En tareas con dinero, clientes, documentos o decisiones, revisa importes, fechas, nombres, identificadores, totales de tabla y caracteres dudosos contra la imagen original.
Convertir imagen a texto es extraer, no generar
Muchas búsquedas mezclan IA, imagen, generador y OCR, pero son trabajos distintos. Un generador de imágenes crea una imagen nueva desde un prompt. La conversión de imagen a texto parte de un archivo visual existente y devuelve texto, campos, tablas, descripciones o respuestas sobre lo que se ve.
La diferencia cambia los riesgos. En generación piensas en estilo, derechos y control creativo. En extracción piensas además en quién posee el archivo, dónde se sube, si se guarda, si puede usarse para entrenamiento, cómo se borra y cómo se verifica el resultado. Una herramienta que parece perfecta para una captura pública puede ser inaceptable para una factura de cliente.
Para texto impreso limpio, el OCR tradicional puede ser la mejor opción. Para una factura fotografiada, quizá necesitas OCR documental que conserve líneas, campos, moneda, fechas y totales. Para un gráfico, un dashboard, una nota manuscrita o una pantalla de error, el OCR puede reconocer algunas palabras pero perder la pregunta real. Un modelo visual puede interpretar contexto, aunque también puede resumir o inferir, así que requiere una verificación más fuerte.
Un flujo profesional no empieza con "cuál es la mejor herramienta". Empieza con cuatro decisiones: si el archivo puede subirse, qué tan difícil es la imagen, qué salida necesitas y cómo se revisará.
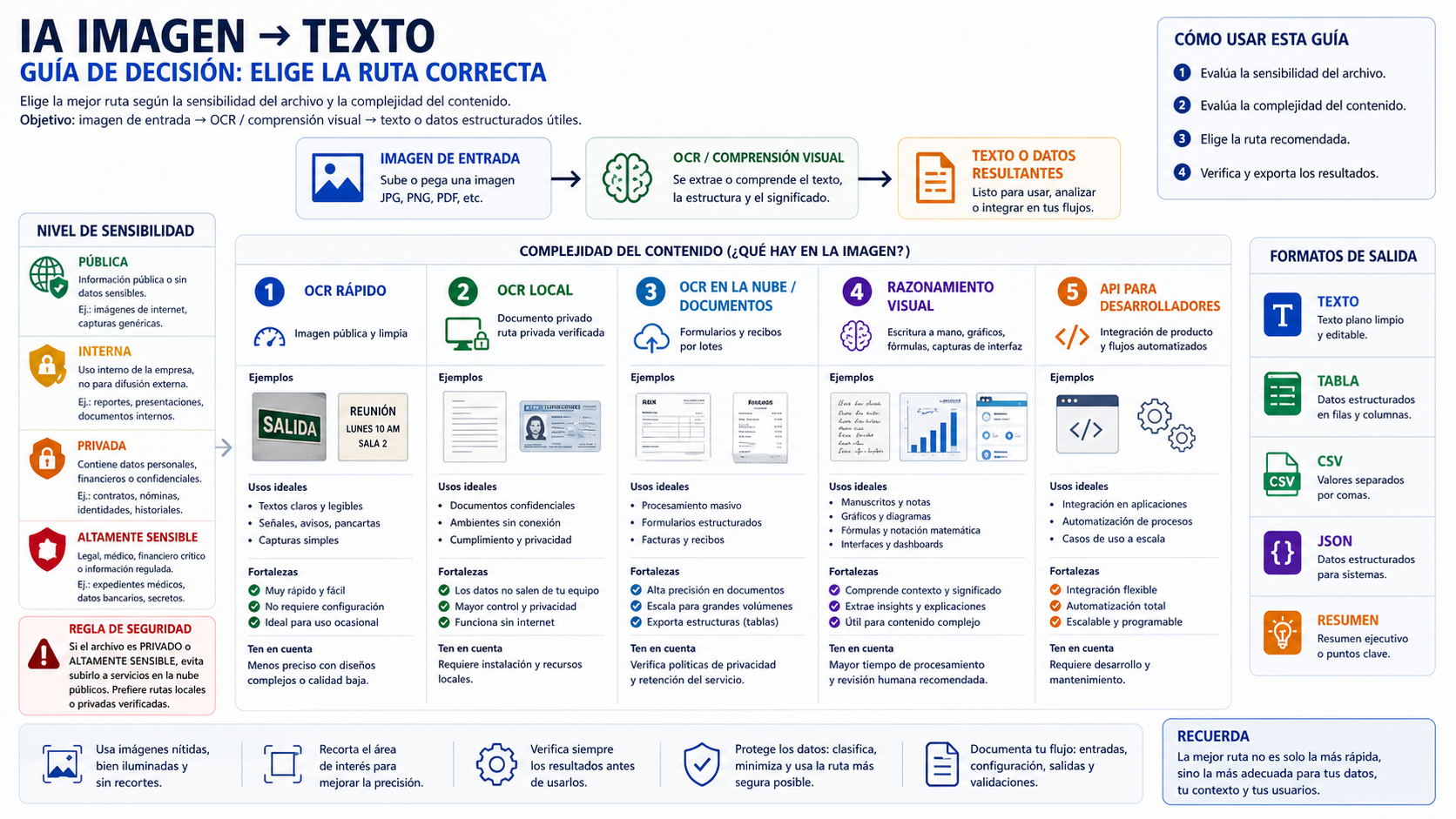
Elige primero por tipo de entrada
No todas las imágenes piden la misma ruta. Una etiqueta nítida y un recibo arrugado son imágenes, pero no deberían pasar por el mismo proceso. Clasificar la entrada evita usar un modelo pesado para una tarea simple o un OCR básico para una imagen que necesita razonamiento.
| Tipo de entrada | Mejor primera ruta | Qué pedir |
|---|---|---|
| Texto impreso limpio, etiquetas, capturas simples | OCR rápido u OCR local | Texto con saltos de línea conservados |
| Escaneos, facturas, recibos, formularios | OCR documental u OCR en la nube | Campos, filas de tabla, orden de página, totales |
| Escritura manual o notas mixtas | Modelo visual con revisión humana | Transcripción y marcas de palabras dudosas |
| Tablas en capturas o imágenes de PDF | OCR más salida estructurada | Markdown, CSV o JSON con encabezados originales |
| Gráficos, dashboards, diagramas, UI | Modelo visual | Título, ejes, leyenda, valores visibles y conclusión soportada |
| Ecuaciones o notación técnica | Modelo visual con formato | LaTeX o transcripción paso a paso |
| Imágenes para accesibilidad | Alt text o descripción larga | Descripción basada en el propósito dentro de la página |
El OCR simple funciona mejor cuando los caracteres se ven bien y la tarea es transcribir. El OCR documental funciona mejor cuando importan layout, páginas, tablas, campos y procesamiento repetible. Los modelos visuales son mejores cuando la imagen contiene una pregunta: qué muestra el gráfico, qué error aparece en la pantalla, qué parte de la tabla es relevante o qué acción sigue.
Aunque vayas a usar una plataforma concreta, esta clasificación debe ir primero. No elijas OpenAI, Gemini, Azure o Google Cloud antes de decidir si el trabajo es OCR, OCR documental, procesamiento local o comprensión visual.
Decide si el archivo puede subirse
Un conversor gratuito no es una política de privacidad. Puede servir para un cartel público, una diapositiva publicada o una captura de bajo riesgo. No debería ser la ruta por defecto para contratos, historiales médicos, nóminas, extractos bancarios, documentos de identidad, pantallas internas, evidencias legales o archivos de clientes.
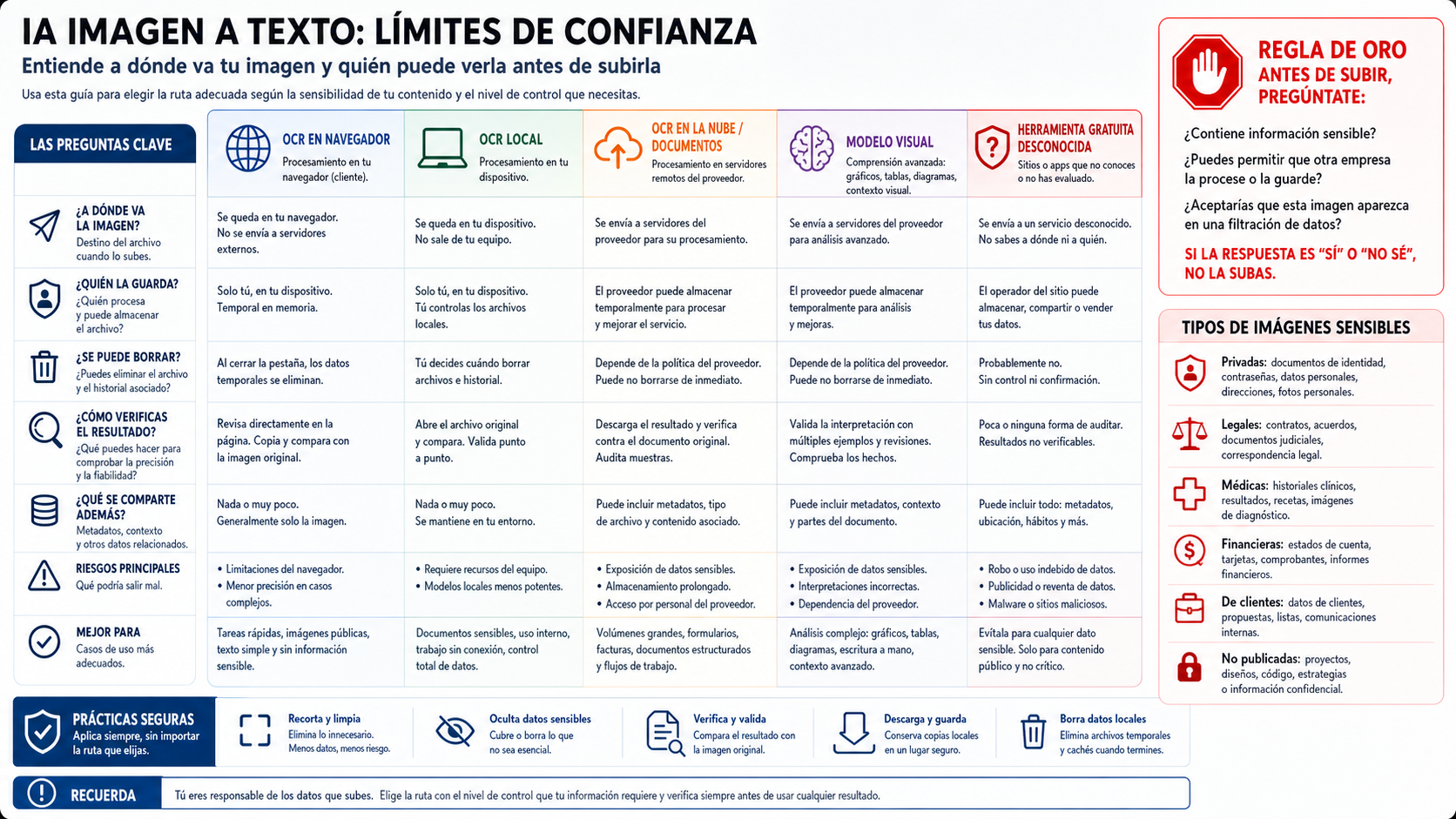
Usa una regla sencilla: si la imagen causaría un problema al aparecer en el correo o chat equivocado, no la subas a un sitio desconocido. Primero revisa quién opera el servicio, si guarda imágenes, si las usa para entrenamiento o mejora, cómo funciona la eliminación, qué derechos concedes y quién responde si el resultado falla.
El OCR local no es mágico, pero cambia la frontera de confianza. Motores como Tesseract y herramientas locales pueden procesar imágenes adecuadas en tu propia máquina o infraestructura. El coste es que debes gestionar idiomas, rotación, contraste, recorte, preprocesado y control de calidad.
El OCR en la nube y los servicios documentales también reciben el archivo, pero suelen ofrecer un contrato operativo más claro que una web aleatoria: cuenta, permisos, logs, región, soporte, borrado, cuotas y facturación. En trabajo profesional, esa claridad puede valer más que una interfaz más cómoda.
Pide la salida que realmente necesitas
"Extrae el texto" suele producir un bloque difícil de reutilizar. Antes de subir, decide dónde irá el resultado. Para lectura, pide texto con líneas preservadas. Para hojas de cálculo, pide CSV o Markdown. Para facturas, pide campos. Para capturas de soporte, pide mensajes visibles, estado de la UI y siguiente acción probable. Para gráficos, pide título, ejes, leyenda, valores visibles, tendencia e incertidumbre.
Prompts compactos:
textExtrae el texto visible exactamente. Conserva saltos de línea. Marca palabras ilegibles como [dudoso].
textConvierte la tabla de esta imagen en Markdown. Mantén los encabezados originales y no inventes celdas.
textExtrae campos de factura como JSON: vendor, invoice_number, date, subtotal, tax, total, currency, line_items. Usa null si un campo no se ve.
textDescribe este gráfico para alguien que no puede verlo. Incluye título, ejes, leyenda, valores visibles, tendencia e incertidumbre.
textEscribe alt text para esta imagen en una página web. Describe el propósito y la información que transmite.
El caso de alt text merece cuidado. No es solo OCR. Una imagen decorativa puede necesitar alt vacío; un gráfico puede necesitar alt corto y descripción larga; una captura usada como evidencia necesita texto visible y contexto. La IA puede ayudar, pero la decisión final es editorial y depende de la página.
Verifica antes de usar el resultado
OCR y modelos visuales fallan de formas previsibles: confunden 0 y O, pierden signos menos, mezclan columnas, omiten decimales, normalizan nombres, adivinan escritura manual o resumen etiquetas parcialmente visibles. Que la respuesta suene fluida no prueba que sea fiel.

Para texto plano, revisa primera y última línea, números, nombres, identificadores, fechas e importes. Para tablas, revisa encabezados, una fila central, la última fila y los totales. Para facturas y recibos, recalcula subtotal, impuestos, total y moneda. Para escritura manual, pide marcas de incertidumbre.
Cuando el archivo importa, usa una segunda ruta. Un OCR local y un modelo visual suelen equivocarse de maneras diferentes. Si ambos coinciden en fecha, total y una fila clave, aumenta la confianza. Si no coinciden, ya tienes una lista concreta para revisión humana.
En flujos de finanzas, soporte, operaciones, legal o clientes, deja una nota de verificación: archivo fuente, ruta usada, prompt o configuración, campos revisados, persona revisora y fecha. No hace falta para toda captura pública, pero sí cuando un dígito equivocado cambia una decisión.
Usa APIs cuando necesites repetibilidad
Un conversor de navegador sirve para una imagen pública puntual. No es un sistema. Si la conversión entra en un producto, una operación recurrente, soporte, finanzas o automatización, necesitas API o pipeline local con autenticación, logs, reintentos, límites, coste, manejo de datos y esquema de salida.
| Necesidad de producción | Mejor ruta | Qué definir |
|---|---|---|
| Mucho texto impreso o etiquetas | OCR API | Preprocesado, idioma, confidence, reintentos |
| Escaneos, formularios, facturas, recibos | OCR documental / Document Intelligence | Orden de páginas, campos, tablas, versión, cola de revisión |
| Preguntas sobre capturas o gráficos | Vision model API | Plantilla de prompt, detalle de imagen, JSON, revisión humana |
| Procesamiento privado por lotes | OCR local o cloud privado aprobado | Almacenamiento, acceso, borrado, auditoría |
| Descripciones accesibles | Vision más revisión editorial | Contexto de página, longitud de alt text, descripción larga |
No diseñes producción sobre promesas como "gratis ilimitado", "100% exacto" o "privado por defecto" sin contrato actual y pruebas propias. Una prueba útil es pequeña: veinte imágenes reales, campos esperados, criterio de aprobación y lista de errores peligrosos.
También conviene separar entradas: archivos públicos rápidos, archivos privados locales, documentos con campos y comprensión visual. Cada entrada puede tener prompt base, reglas de subida, logs y revisión. Así el equipo no depende de la web que hoy aparezca arriba en una búsqueda.
La calidad de la imagen también forma parte de la ruta. Inclinación, reflejos, baja resolución, compresión, recortes, idiomas mezclados y escritura difícil reducen la fiabilidad. A veces la mejor mejora no es cambiar de modelo, sino volver a capturar, recortar, dividir páginas o aumentar resolución.
Checklist de elección segura
Antes de usar cualquier herramienta, responde:
- ¿La imagen es pública, desechable, de cliente, regulada, interna, no publicada o con datos personales?
- ¿Necesitas texto, tabla, JSON, alt text, resumen o respuesta visual?
- ¿Es texto impreso, documento, escritura manual, gráfico, captura, fórmula o contenido mixto?
- ¿Quién controla subida, almacenamiento, borrado, soporte y facturación?
- ¿Qué campos revisarás contra la imagen original?
- ¿Qué harás si OCR y modelo visual discrepan?
- ¿Puedes reproducir el resultado con la misma ruta y el mismo prompt?
Si no puedes responder la parte de subida y verificación, no avances por velocidad. La mejor herramienta no es la más rápida; es la que encaja con el riesgo del archivo, la complejidad visual y el uso posterior.
Preguntas frecuentes
¿Convertir imagen a texto es lo mismo que generar imágenes?
No. Convertir imagen a texto empieza con una imagen y devuelve texto, campos, tablas, descripciones o respuestas. Generar imágenes empieza con un prompt y crea una imagen nueva.
¿Cuál es la ruta más segura para documentos privados?
OCR local o una ruta privada aprobada de OCR/documentos. Para archivos legales, médicos, financieros, de cliente, identidad o internos, la frontera de subida importa más que la velocidad.
¿Cuándo es mejor OCR que un modelo visual?
Cuando el texto es limpio y el objetivo es transcripción exacta. El OCR es más simple de revisar y escalar. Usa un modelo visual para tablas complejas, gráficos, escritura manual, ecuaciones, UI o contexto.
¿La IA puede leer escritura manual?
Muchas veces sí, pero exige verificación. Pide que marque palabras dudosas y revisa nombres, importes, fechas y cualquier dato médico, legal o financiero contra la imagen.
¿Cómo extraigo tablas de capturas?
Pide Markdown, CSV o JSON con encabezados originales. Después revisa encabezados, una fila central, la última fila y los totales. Los errores de tablas suelen ser estructurales.
¿Alt text es OCR?
No. OCR extrae caracteres visibles. Alt text describe la función y la información de la imagen en su contexto. Un gráfico, una imagen decorativa, un producto y una captura de evidencia requieren tratamientos distintos.
¿Con qué API debería empezar un desarrollador?
Empieza por el trabajo. OCR o document OCR para imágenes y documentos con mucho texto; vision model API para razonamiento visual y respuestas estructuradas; OCR local o ruta privada cuando el archivo no debe salir.
¿Puedo usar una herramienta gratuita para archivos de trabajo?
Solo para archivos públicos o de bajo riesgo. Para documentos de negocio, revisa operador, privacidad, retención, borrado, uso en entrenamiento, derechos y soporte. Gratis no significa seguro.