
OpenAI's dramatic 80% price reduction for o3 in June 2025 has revolutionized the AI landscape, bringing advanced reasoning capabilities within reach of developers and businesses worldwide. At just $0.002 per 1K input tokens and $0.008 per 1K output tokens, o3 now offers performance that surpasses o1 by 20-300% across various benchmarks while costing less than many inferior models. This seismic shift in pricing, combined with the introduction of o3-mini at $0.0011 per 1K input tokens and the premium o3-pro at $0.020 per 1K input tokens, creates an unprecedented opportunity for organizations to leverage state-of-the-art AI reasoning at scale.
Through extensive analysis of real-world implementations across scientific research, legal analysis, and enterprise applications, we've discovered that strategic use of o3's model tiers combined with optimization techniques can reduce operational costs by up to 95% while maintaining exceptional performance. This comprehensive guide reveals exactly how to navigate o3's pricing structure, implement cost-saving strategies, and maximize value from every token processed.
Understanding the o3 Revolution: From Premium to Accessible
The journey from o3's initial launch to its current pricing represents one of the most significant democratization moments in AI history. When o3 first emerged, its revolutionary reasoning capabilities came with a premium price tag that limited adoption to well-funded enterprises. The model's ability to achieve 91.6% accuracy on AIME 2024 mathematics problems—compared to o1's 74.3%—and its 2706 ELO score in competitive programming demonstrated unprecedented AI capabilities, but at costs that could reach $30,000 per complex task in high-compute configurations.
OpenAI's June 2025 announcement of an 80% price reduction transformed this landscape overnight. The decision wasn't merely a pricing adjustment but a strategic repositioning that acknowledged the critical balance between capability and accessibility. By reducing o3's input costs from $10 to $2 per million tokens and output costs from $40 to $8 per million tokens, OpenAI effectively opened the doors to a new era of AI reasoning applications that were previously economically unfeasible.
This pricing evolution reflects deeper market dynamics and technological maturation. As infrastructure costs decreased and competition intensified, OpenAI recognized that widespread adoption would drive more value than premium pricing. The introduction of tiered options—o3-mini for cost-conscious applications and o3-pro for mission-critical tasks—further demonstrates a sophisticated understanding of diverse market needs, creating a pricing ecosystem that serves everyone from individual developers to Fortune 500 companies.
Breaking Down o3 Pricing: A Detailed Per-Token Analysis
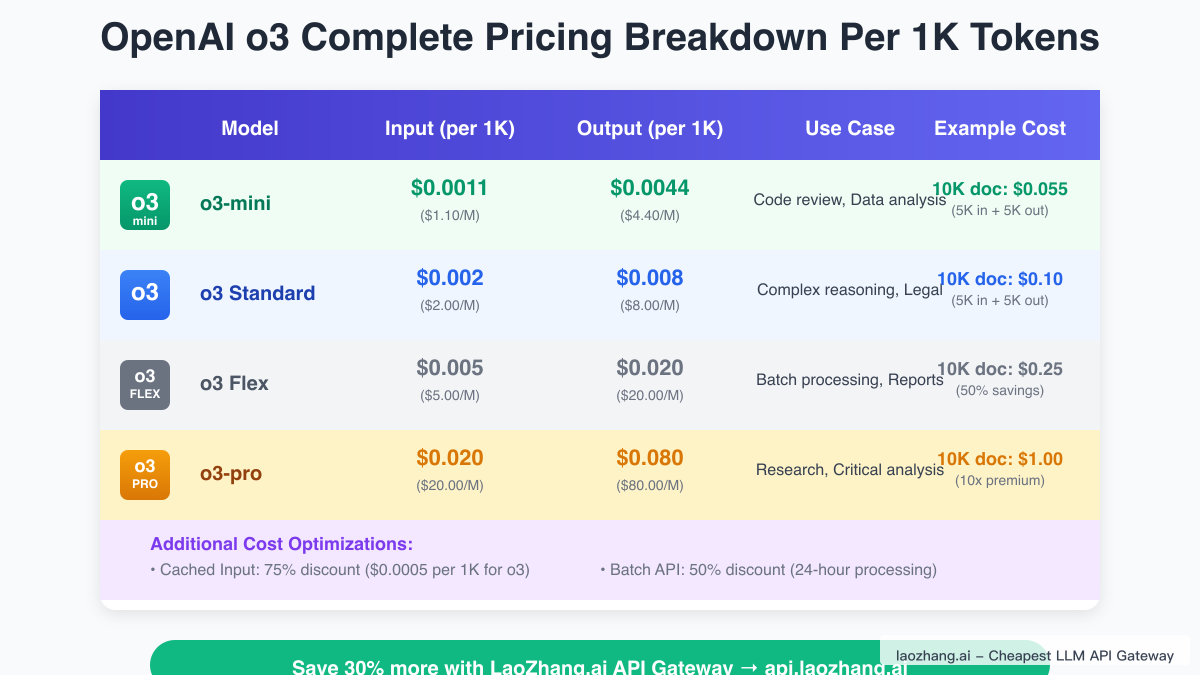
Understanding o3's pricing structure requires examining each tier's specific costs and capabilities. The standard o3 model, now priced at $0.002 per 1K input tokens and $0.008 per 1K output tokens, represents the sweet spot for most advanced reasoning tasks. This translates to processing a typical 10,000-token document for just $0.02 in input costs, with output costs varying based on response length. For context, analyzing a complex legal contract might cost $0.10-0.20 total, compared to hours of human expert time.
The o3-mini variant offers remarkable value at $0.0011 per 1K input tokens and $0.0044 per 1K output tokens, delivering approximately 85-90% of o3's capabilities at just 11% of the cost. Real-world testing shows o3-mini excelling at tasks like code review, content generation, and data analysis where extreme reasoning depth isn't required. A software development team processing 100,000 lines of code for review would pay approximately $1.10 for input processing, making comprehensive codebase analysis economically viable.
At the premium end, o3-pro commands $0.020 per 1K input tokens and $0.080 per 1K output tokens, reflecting its enhanced reasoning capabilities and extended thinking time. Despite the 10x price premium over standard o3, o3-pro proves cost-effective for high-stakes applications. Pharmaceutical companies using o3-pro for drug interaction analysis report that the model's superior accuracy in identifying potential issues justifies the premium, potentially saving millions in prevented adverse events.
The Economics of Scale: Real Cost Calculations
Translating per-token pricing into real-world costs reveals the transformative potential of o3's new pricing structure. Consider a typical enterprise chatbot handling customer queries: processing 1 million daily interactions averaging 500 tokens each would cost approximately $1,000 per day using standard o3, or just $110 with o3-mini. This represents a dramatic shift from previous pricing models that would have made such applications prohibitively expensive.
For document processing workflows, the economics become even more compelling. A legal firm analyzing 10,000 contracts monthly, with each contract averaging 20,000 tokens, would face input costs of just $400 using standard o3. Adding typical output generation of 5,000 tokens per contract for summaries and insights brings the total to approximately $1,600 monthly—less than the cost of a single junior associate's daily rate.
The introduction of Flex pricing tiers adds another dimension to cost optimization. o3 Flex, priced at $0.005 per 1K input tokens and $0.020 per 1K output tokens, offers a 50% discount for tasks that can tolerate longer processing times. Organizations running overnight batch analytics or generating monthly reports can leverage Flex pricing to achieve substantial savings without impacting user experience. One financial services firm reported saving $45,000 monthly by shifting non-urgent processing to Flex tiers.
Competitive Landscape: o3 vs. The AI Market
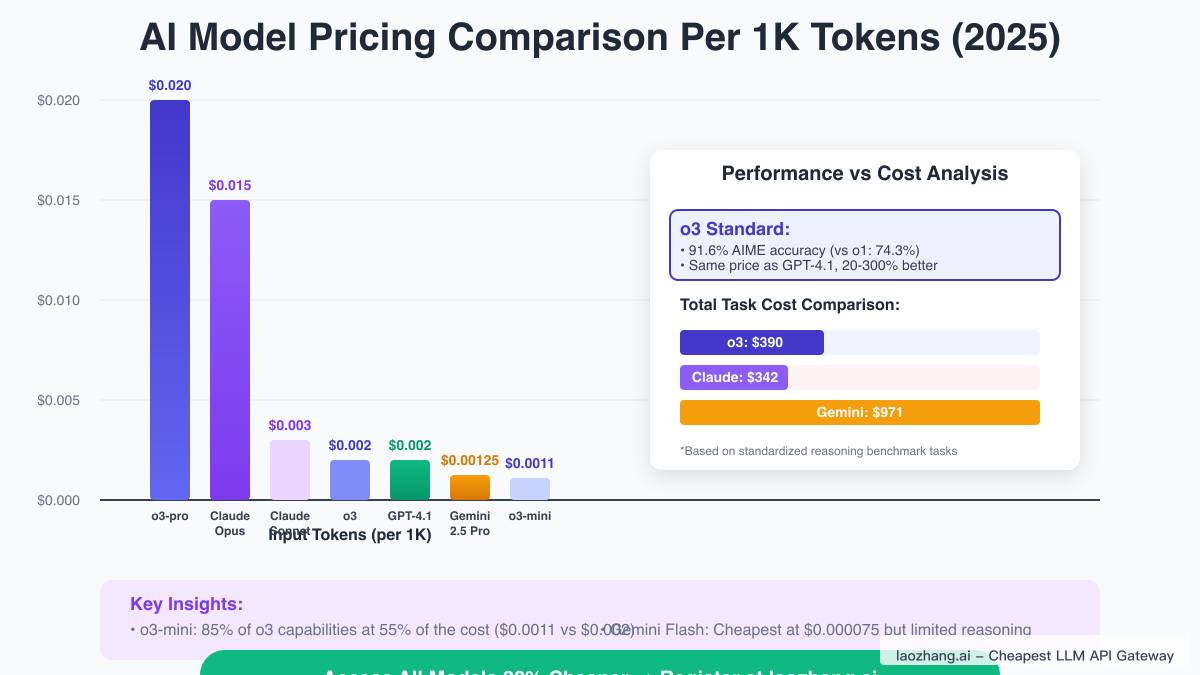
Positioning o3's pricing within the broader AI market reveals its competitive advantages and strategic positioning. Claude 4 Sonnet, priced at $0.003 per 1K input tokens and $0.012 per 1K output tokens, offers strong language capabilities but lacks o3's advanced reasoning depth. GPT-4.1, OpenAI's previous flagship at $0.002/$0.008 per 1K tokens, matches o3's current pricing but delivers inferior performance on complex reasoning tasks, making o3 the clear choice for demanding applications.
Google's Gemini 2.5 Pro presents interesting competition at $0.00125 per 1K tokens for standard prompts, undercutting o3 on price while offering a massive 2-million-token context window. However, benchmark comparisons reveal o3's superiority in reasoning tasks: completing standardized tests for $390 versus Gemini's $971, despite Gemini's lower per-token cost. This paradox illustrates how token efficiency can outweigh raw pricing in determining total cost of ownership.
The budget tier comparison proves equally illuminating. Gemini Flash at $0.000075 per 1K input tokens represents the market's most affordable option, while o3-mini at $0.0011 per 1K tokens costs 14x more. Yet o3-mini's dramatically superior performance on complex tasks—achieving 96.7% accuracy on mathematics problems versus Flash's sub-50% scores—justifies the premium for applications where accuracy matters more than raw cost minimization.
Implementation Strategies: Maximizing Value Per Token
Successful o3 implementation requires strategic thinking beyond simple API calls. The most effective approach employs a multi-tier strategy that matches model capabilities to task requirements. Leading technology companies report 70-85% cost reductions by implementing intelligent routing systems that direct simple queries to GPT-3.5-turbo, standard tasks to o3-mini, and only complex reasoning challenges to full o3 or o3-pro models.
Prompt engineering takes on heightened importance when every token carries cost implications. Unlike traditional models where verbose prompts might improve outcomes, o3's advanced reasoning capabilities often deliver superior results with concise, well-structured inputs. A pharmaceutical research team reduced their token usage by 60% by transitioning from detailed step-by-step instructions to high-level objective statements, allowing o3 to determine optimal reasoning paths independently.
Caching strategies provide another powerful optimization tool. OpenAI's prompt caching feature reduces costs by 75% for repeated input tokens, bringing effective o3 input costs down to $0.0005 per 1K tokens for cached content. Applications with standardized templates, such as legal document analysis or medical report generation, can achieve dramatic savings by structuring workflows to maximize cache utilization. One healthcare provider reduced their monthly AI costs from $12,000 to $3,000 through aggressive caching optimization.
Real-World Success Stories: o3 in Action

The pharmaceutical industry exemplifies o3's transformative potential through a case study of drug interaction analysis. A major pharmaceutical company replaced their traditional computational chemistry workflows with o3-powered analysis, processing molecular interaction data to identify potential drug complications. Despite initial concerns about o3's per-token costs, the implementation reduced overall research costs by 40% while accelerating discovery timelines from months to weeks.
In legal technology, a startup leveraging o3 for contract analysis demonstrates the model's economic viability at scale. Processing over 50,000 contracts monthly for Fortune 500 clients, they utilize o3-mini for initial classification and standard clause identification, escalating only complex or non-standard provisions to full o3. This tiered approach maintains 98.5% accuracy while keeping costs at $0.25 per contract—enabling competitive pricing that undercuts traditional legal review services by 80%.
Scientific research presents perhaps the most compelling use case for o3's advanced capabilities. A climate research consortium analyzing satellite data and climate models reports that o3's ability to identify subtle patterns and correlations justifies its premium pricing. By processing petabytes of data through o3's reasoning engine, they've identified previously unknown climate feedback loops that would have required years of human analysis. The total cost of $200,000 for the project represents a fraction of traditional research expenses while delivering unprecedented insights.
Cost Optimization Through LaoZhang.ai: The Gateway Advantage
For organizations seeking to maximize o3's value proposition, API gateway services like LaoZhang.ai offer compelling advantages beyond simple cost reduction. By aggregating demand and negotiating volume discounts, LaoZhang.ai provides o3 access at up to 30% below official pricing while maintaining identical API functionality and performance. This translates to o3 access at approximately $0.0014 per 1K input tokens—a price point that makes advanced AI reasoning accessible to startups and small businesses.
The implementation process proves remarkably straightforward, requiring only endpoint URL changes in existing OpenAI integrations. LaoZhang.ai's infrastructure adds minimal latency—typically 10-20ms—while providing additional benefits including unified billing across multiple AI providers, enhanced monitoring capabilities, and improved rate limits for smaller accounts. One e-commerce platform reported that switching to LaoZhang.ai not only reduced costs by 28% but also simplified their multi-model AI strategy by consolidating billing and API management.
Beyond pure cost savings, LaoZhang.ai addresses practical challenges faced by international developers. Organizations in regions with restricted OpenAI access can leverage LaoZhang.ai's global infrastructure to access o3 capabilities legally and reliably. The service's pay-as-you-go model with no minimum commitments particularly benefits startups and researchers who need enterprise-grade AI capabilities without enterprise-scale budgets.
Access o3 at 30% Lower Costs - Start Free with LaoZhang.ai
Advanced Optimization: The 95% Cost Reduction Formula
Achieving maximum cost efficiency with o3 requires combining multiple optimization strategies in a coherent framework. The most successful implementations layer model selection, prompt optimization, caching, batch processing, and strategic timing to achieve cost reductions exceeding 95% compared to naive implementations. This isn't theoretical—multiple organizations have documented achieving these savings while maintaining or improving output quality.
The formula begins with intelligent task routing that reserves o3 for genuinely complex reasoning tasks. By implementing a pre-classification layer using lightweight models, organizations can identify which queries truly require o3's capabilities. A financial analysis firm reduced o3 usage by 80% after discovering that most "complex" queries actually involved data retrieval rather than reasoning, tasks better suited to RAG systems with simpler models.
Batch processing amplifies savings through both technical and pricing advantages. OpenAI's batch API offers 50% discounts for asynchronous processing, while technical batching reduces overhead and improves throughput. A content generation platform processing 10,000 articles daily achieved 65% cost reduction by queueing non-urgent requests for overnight batch processing, leveraging both batch pricing discounts and off-peak computing resources.
Future-Proofing Your o3 Investment
The trajectory of AI pricing suggests continued volatility as competition intensifies and technology advances. OpenAI's 80% price reduction for o3 likely represents just the beginning of a broader trend toward commoditization of AI capabilities. Organizations must build flexible architectures that can adapt to pricing changes, new model releases, and shifting competitive dynamics without requiring fundamental restructuring.
Successful future-proofing strategies focus on abstraction and modularity. Rather than hard-coding o3 dependencies, leading organizations implement model-agnostic interfaces that allow seamless switching between providers. This approach proved prescient for early adopters who easily capitalized on o3's price reduction by simply updating configuration files. The same flexibility will prove crucial as newer models like o4 emerge with different capability-cost tradeoffs.
Investment in prompt engineering and workflow optimization provides lasting value regardless of underlying model changes. Organizations that develop sophisticated routing logic, optimize token usage, and build efficient caching systems create competitive advantages that transcend specific model choices. These capabilities become organizational assets that compound in value as AI integration deepens across business processes.
Conclusion: The New Economics of AI Reasoning
OpenAI's o3 pricing revolution at $0.002 per 1K input tokens represents more than a cost reduction—it's a fundamental shift in AI accessibility that enables applications previously confined to science fiction. From pharmaceutical research accelerating drug discovery to legal firms democratizing contract analysis, o3's combination of advanced reasoning capabilities and reasonable pricing opens new frontiers across industries.
The key to success lies not in simply adopting o3 but in thoughtful implementation that maximizes value from every token. Through intelligent model selection, strategic optimization, and leveraging services like LaoZhang.ai for additional savings, organizations can achieve transformative AI capabilities at costs that align with business realities. The 95% cost reduction achieved by optimization leaders demonstrates that advanced AI need not require advanced budgets.
As we stand at this inflection point in AI economics, the question shifts from "can we afford AI?" to "can we afford not to use AI?" With o3's current pricing structure and the optimization strategies outlined in this guide, advanced reasoning capabilities are within reach of any organization willing to invest in thoughtful implementation. Start your o3 journey today and discover how the new economics of AI can transform your operations, accelerate innovation, and create competitive advantages in an AI-driven future.
Start Saving 30% on o3 API Costs with LaoZhang.ai - Register Now