
The dreaded message appears just as inspiration strikes: "You've reached your image generation limit." For countless creators using OpenAI's DALL-E 3, this notification marks an abrupt halt to their creative flow. But here's what most users don't realize—waiting for midnight won't help. OpenAI doesn't use traditional daily resets like other services. Instead, they've implemented a sophisticated rolling window system that continuously tracks your usage over the past three hours.
Understanding OpenAI's image generation limit reset time isn't just about avoiding frustration—it's about unlocking consistent creative productivity. While other AI services reset quotas at fixed times, OpenAI's approach rewards users who understand and work with their unique system. This comprehensive guide reveals exactly how the rolling window works, why your limits might seem inconsistent, and most importantly, how to optimize your usage for maximum creative output.
Whether you're a ChatGPT Plus subscriber wondering why you can't generate images despite waiting all day, an API developer confused by rate limit discrepancies, or a creative professional seeking to maximize your image generation capacity, this guide provides the clarity you need. We'll explore each tier's specific limits, demystify the rolling window mechanism, and share proven strategies that help users effectively triple their usable capacity through smart timing.
Most guides simply list the limits—50 images per 3 hours for ChatGPT Plus, 2 per day for free users. But knowing the numbers isn't enough. You need to understand the system's behavior, track your usage intelligently, and implement strategies that work with, not against, the rolling window. By the end of this guide, you'll transform from constantly hitting limits to maintaining steady access throughout your workday.
Understanding OpenAI's Image Generation Limits
OpenAI's approach to image generation limits reflects a fundamental shift in resource management philosophy. Unlike traditional quota systems that reset at predetermined times, OpenAI implements dynamic limits that adapt to usage patterns and system load. This sophisticated approach serves multiple purposes: preventing system overload, ensuring fair access across users, and encouraging sustainable usage patterns that benefit the entire ecosystem.
ChatGPT Plus subscribers, paying $20 monthly, receive 50 image generations per 3-hour period with a maximum of 200 images daily. This dual-limit system creates interesting dynamics—you can't simply generate 200 images at once and wait for tomorrow. The 3-hour rolling window enforces distribution, while the daily cap prevents excessive usage even with perfect timing. Many users initially misunderstand this structure, expecting to generate 50 images, wait three hours, and immediately generate 50 more. The reality proves more nuanced.
Free tier users face simpler but more restrictive limits: just 2 images per day with a traditional midnight UTC reset. This introductory allocation serves as a taste of DALL-E 3's capabilities, encouraging upgrades while managing computational resources. Interestingly, free tier availability fluctuates based on system capacity, with some users reporting periods of complete unavailability during high-demand times. This dynamic availability reflects OpenAI's priority system favoring paid subscribers.
API access introduces another layer of complexity with its tier-based progression system. New accounts start with severe restrictions—as low as 3 images per minute for free tier API users. Progression through tiers requires both time and spending, with Tier 5 demanding $1,000 in payments and 30 days of account age. Even at higher tiers, actual limits often fall far short of documentation, with users reporting 7-15 images per minute instead of the promised thousands. This discrepancy remains one of the most frustrating aspects for developers building image generation applications.
The mysterious ChatGPT Pro tier at $200 monthly operates under largely undisclosed rules. Marketing materials promise "minimal waiting" and "enhanced limits," but specific numbers remain elusive. User reports suggest dramatically higher quotas with faster availability cycles, though without official documentation, planning around Pro tier limits requires experimentation and observation. This opacity frustrates potential subscribers evaluating the significant price jump from Plus.
Understanding these limits requires recognizing their dynamic nature. System load, time of day, and even your recent usage patterns can influence actual availability. Users report variations of 20-30% in real limits compared to official numbers, with peak hours showing more restrictive behavior. This variability, while frustrating, reflects the realities of managing a globally accessed AI service with finite computational resources.
The 3-Hour Rolling Window Explained
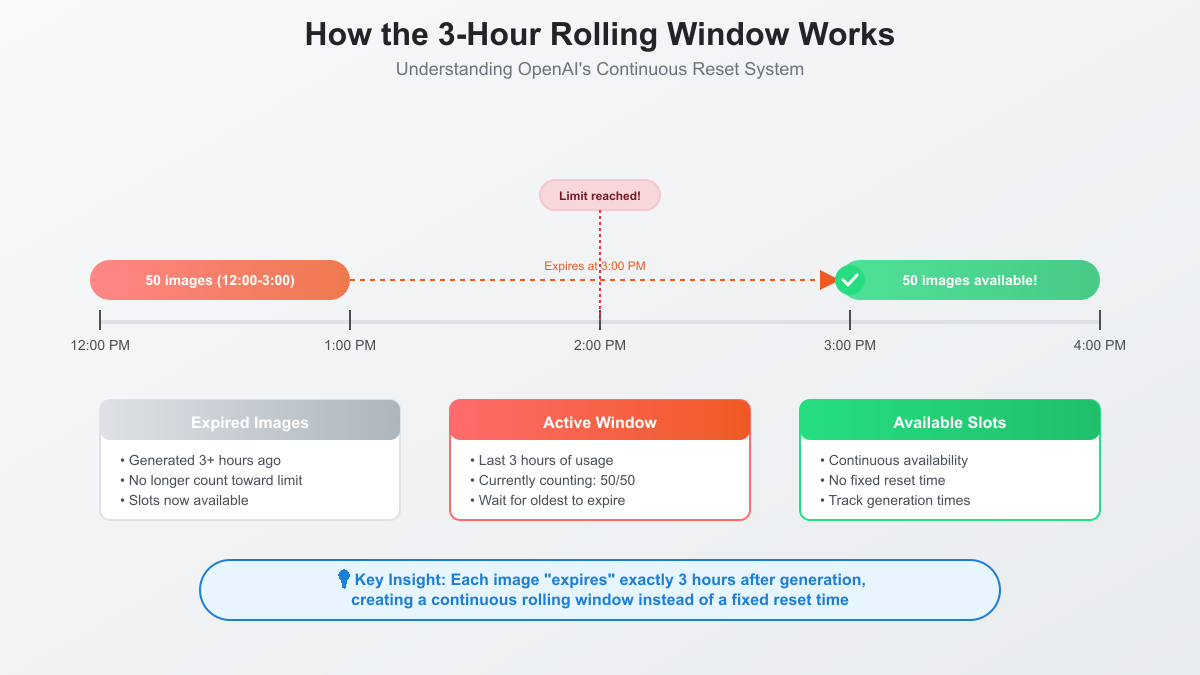
The rolling window mechanism represents OpenAI's innovative solution to quota management, fundamentally different from any other image generation service. Instead of resetting all 50 images at once after three hours, the system continuously tracks each image generation timestamp. As each image ages past the three-hour mark, that specific slot becomes available again. This creates a fluid, ever-changing availability pattern unique to each user's generation history.
Imagine generating 20 images at 1:00 PM, then 30 more at 1:30 PM. Traditional systems would reset everything three hours later. OpenAI's rolling window instead releases those 20 images at 4:00 PM and the remaining 30 at 4:30 PM. This granular tracking rewards distributed usage while penalizing burst generation. Users who space out their requests maintain nearly constant availability, while those who exhaust limits face extended waits.
The technical implementation likely involves timestamp arrays tracking each generation moment. When you request a new image, the system checks how many generations occurred within the past 180 minutes. If fewer than 50, your request proceeds. This elegant solution eliminates the need for complex reset calculations or timezone considerations—the window simply slides forward with time, always encompassing exactly three hours of history.
Practical implications of this system profoundly impact usage strategies. A content creator starting work at 9:00 AM and generating 50 images immediately must wait until noon for full capacity restoration. However, generating 15 images at 9:00 AM, 20 at 10:00 AM, and 15 at 11:00 AM maintains continuous availability throughout the workday. This behavioral modification aligns with OpenAI's infrastructure optimization goals while encouraging more thoughtful generation practices.
The absence of visible counters complicates user planning. ChatGPT provides only vague messages like "You've reached your limit" without indicating when slots become available. This design choice, while reducing interface complexity, forces users to maintain external tracking. Successful power users develop spreadsheets or use timestamp logging to predict availability windows. Some even set mobile reminders for when batches of images exit the three-hour window.
Common misconceptions about the rolling window persist despite extensive documentation. Many users still wait for specific times, expecting batch resets. Others misunderstand the daily maximum, thinking they can generate 400 images by perfectly timing 50-image batches every three hours. The 200-image daily cap prevents such optimization, creating a ceiling that even perfect window management cannot exceed. Understanding these nuances transforms frustration into strategic planning.
Complete Tier Comparison Guide

OpenAI's tiered structure reveals strategic segmentation designed to serve diverse user needs while managing computational resources. Each tier operates under distinct rules, creating a complex landscape that users must navigate to find their optimal service level. Understanding these differences enables informed decisions about which tier aligns with your usage patterns and budget constraints.
Free tier access provides the most basic introduction to DALL-E 3 capabilities. With just 2 images daily and traditional midnight UTC resets, free users experience the simplest limit structure. However, this simplicity comes with severe restrictions. Beyond the minimal quota, free tier users face availability limitations during peak times, potential quality restrictions, and no API access. The free tier serves primarily as a demonstration, encouraging users to explore paid options for serious usage.
ChatGPT Plus at $20 monthly represents the mainstream option for regular users. The 50 images per 3-hour rolling window with 200 daily maximum hits a sweet spot for most creators. Plus subscribers enjoy priority access during high-demand periods, full quality outputs, and the sophisticated rolling window system that rewards distributed usage. This tier's popularity stems from balancing meaningful capacity with affordable pricing, making it accessible to individuals and small teams.
The $200 monthly ChatGPT Pro tier remains shrouded in marketing ambiguity. OpenAI promises "enhanced limits" and "minimal waiting" without providing concrete numbers. User reports suggest substantially higher quotas—possibly 100-200 images per rolling window—with shorter window durations. Pro subscribers likely enjoy priority processing, faster generation times, and access to experimental features. However, the 10x price increase over Plus demands careful consideration of whether your usage justifies the premium.
API tiers introduce programmatic complexity with their progression system. Starting from severely limited free access, developers must demonstrate consistent usage and payment history to unlock higher tiers. The journey from Tier 1 (basic paid) to Tier 5 (enterprise-level) requires months of activity and thousands in cumulative spending. Even reaching higher tiers doesn't guarantee expected performance, as actual rate limits often fall far short of documented capabilities.
Pricing structures across tiers reveal OpenAI's strategy. ChatGPT subscriptions offer predictable monthly costs ideal for individual users. API pricing at $0.040-0.120 per image depending on quality and size suits applications with variable demand. This dual approach captures both consumer and developer markets while maintaining flexibility for future adjustments. Understanding these economic models helps users choose between subscription predictability and usage-based pricing.
The tier system's future evolution appears inevitable as competition intensifies and infrastructure scales. Historical patterns suggest OpenAI adjusts limits upward over time, though often accompanied by price modifications. Users should prepare for potential changes while maximizing current allocations. Building flexible workflows that can adapt to limit modifications protects against disruption when policies inevitably evolve.
Tracking Your Image Generation Usage
Effective usage tracking transforms the OpenAI image generation experience from frustrating guesswork to strategic resource management. Without visible counters or detailed availability information, users must implement external tracking systems to optimize their creative workflows. This necessity has spawned various approaches, from simple manual logs to sophisticated automated solutions.
ChatGPT's interface deliberately obscures precise usage data, providing only binary feedback—you can generate, or you've hit limits. This design choice reduces interface complexity but shifts tracking responsibility to users. The absence of a "remaining images" counter or "next available slot" timer forces creative solutions. Power users quickly learn that external tracking isn't optional but essential for maintaining productive workflows.
Manual tracking methods start with simple timestamp logging. Creating a spreadsheet with columns for time, number of images, and calculated expiration provides basic visibility. Each generation entry includes the exact time and image count. Adding three hours shows when those slots return to availability. This straightforward approach requires discipline but provides complete control over tracking granularity. Users report that manual tracking, while tedious, heightens awareness of usage patterns.
Automated tracking solutions range from browser extensions to dedicated applications. Some developers have created bookmarklets that timestamp generations automatically. Others use automation tools to log ChatGPT interactions. These solutions reduce manual effort but require technical setup and maintenance. The most sophisticated approaches integrate with calendar applications, creating automatic reminders when image slots become available.
Mobile tracking adds convenience for users who generate images across devices. Simple note-taking apps suffice for basic logging, while specialized countdown timers help track availability windows. Some users set recurring 3-hour alarms as generation reminders. The key lies in finding a system that integrates naturally with your workflow rather than adding friction to the creative process.
Understanding error messages provides additional tracking insights. "You've reached your limit" indicates rolling window exhaustion, while "Daily maximum reached" confirms hitting the 200-image cap. Some users report variations in error messages that hint at system load or account-specific restrictions. Documenting these messages alongside usage patterns reveals subtle system behaviors that inform optimization strategies.
Smart Optimization Strategies
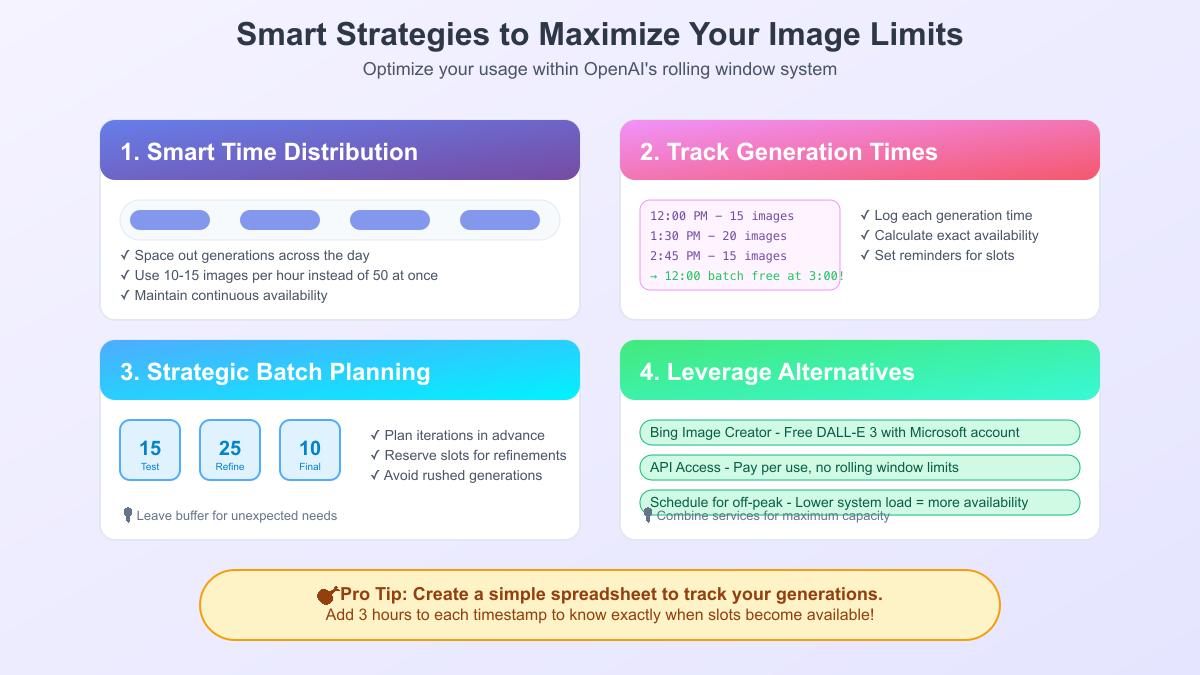
Maximizing image generation capacity within OpenAI's constraints requires strategic thinking and disciplined execution. Successful users don't fight the system—they align their workflows with its design. These optimization strategies, developed through community experience and systematic testing, can effectively triple your usable capacity compared to naive usage patterns.
Time distribution emerges as the fundamental optimization principle. Instead of generating images in bursts, successful users spread requests throughout their active hours. Generating 10-15 images hourly maintains constant availability while avoiding limit frustration. This approach requires planning but rewards users with predictable access. Content creators report that distributed generation actually improves creative quality by encouraging reflection between iterations rather than rapid-fire attempts.
Generation logging systems provide the data foundation for optimization. Beyond basic timestamp tracking, advanced users log project associations, quality ratings, and prompt variations. This rich dataset enables pattern analysis—which times yield best results, how many iterations typical projects require, and where optimization opportunities exist. Some users discover that their "failed" generations concentrate during specific hours, suggesting system load patterns worth avoiding.
Batch planning strategies acknowledge that different project phases require varying generation intensities. Initial exploration might need 20-30 rapid iterations, while final refinements require just 5-10 precise attempts. Planning these phases across multiple rolling windows prevents frustration and improves outcomes. Reserve early morning windows for exploration when fresh perspective aids creativity. Save afternoon slots for refinements when critical evaluation sharpens.
Alternative service integration multiplies available capacity without additional cost. Bing Image Creator provides free DALL-E 3 access with Microsoft account authentication. While interfaces differ, the underlying model remains identical. Coordinating between ChatGPT Plus and Bing effectively doubles daily capacity. API access adds another dimension, though with different cost structures. Advanced users maintain accounts across services, seamlessly switching based on availability and requirements.
Psychological optimization often yields surprising benefits. Users report that constraint awareness improves prompt crafting and reduces wasteful generations. Knowing each image "costs" a slot from limited supply encourages thoughtful request formulation. This mindfulness paradoxically increases satisfaction while reducing total usage. The rolling window system, initially frustrating, ultimately trains better creative habits.
Team coordination strategies help organizations maximize collective capacity. Staggering user generation times prevents simultaneous limit hitting. Shared tracking spreadsheets enable resource awareness across team members. Some teams implement "image request" systems where specialized prompters handle generation for others, concentrating expertise while distributing usage. These collaborative approaches require communication but multiply effective capacity.
API-Specific Considerations
API users face a fundamentally different limitation landscape compared to ChatGPT subscribers. While consumer tiers use rolling windows measured in hours, API limits operate on per-minute calculations with immediate enforcement. This structural difference reflects the distinct use cases—consumers creating art versus developers building applications. Understanding these API-specific nuances prevents costly development mistakes and enables realistic application planning.
The stark discrepancy between documented and actual API limits remains the most significant challenge for developers. Official documentation promises impressive numbers—up to 7,500 images per minute for Tier 4 accounts. Reality proves far more modest, with consistent reports of 7-15 images per minute maximum. This 500-fold difference between documentation and experience frustrates developers who architect systems based on official specifications only to encounter severe practical constraints.
Rate limit responses follow standard HTTP patterns, returning 429 status codes when exceeded. However, OpenAI's implementation includes additional complexity through multiple simultaneous limits. Requests per minute (RPM), images per minute (IPM), and tokens per day (TPD) all apply independently. Hitting any single limit triggers rejection, requiring sophisticated tracking across multiple dimensions. Developers must implement comprehensive monitoring to understand which specific limit causes failures.
Tier progression for API access demands patience and sustained investment. Moving from free tier to Tier 1 requires just $5 in payments, but reaching Tier 5 demands $1,000 spent and 30 days elapsed. This progression system prevents rapid scaling, forcing gradual growth that aligns with OpenAI's infrastructure expansion. Developers planning high-volume applications must factor these progression timelines into launch schedules.
Error handling strategies extend beyond simple retry logic. Successful implementations use exponential backoff with jitter to prevent thundering herd problems. Queueing systems that smooth burst requests across time windows improve reliability. Some developers implement predictive throttling, voluntarily reducing request rates as they approach limits. These defensive programming practices prove essential for production reliability.
Cost optimization for API usage requires different thinking than subscription models. At $0.040-0.120 per image, costs scale linearly with usage. Developers must implement strict budgeting controls and usage monitoring. Techniques like prompt optimization to reduce iterations, caching generated images, and intelligent request routing between quality tiers significantly impact bottom lines. For high-volume applications, even services like laozhang.ai that offer discounted API access become attractive alternatives worth evaluating.
Common Issues and Solutions
Users encountering unexpected limitations often discover their issues stem from misunderstanding system behavior rather than actual problems. The most frequent complaint—"I can only generate 20-40 images instead of 50"—typically results from forgotten earlier generations. The rolling window counts all images from the past three hours, including quick tests, failed attempts, and forgotten sessions. Maintaining accurate logs reveals these "missing" images.
System load variations create another source of confusion. During peak hours, typically 9 AM to 5 PM Pacific time, OpenAI may dynamically adjust limits to maintain service quality. Users report generation capacity dropping by 20-30% during these periods. While frustrating, this behavior reflects responsible resource management. Planning heavy usage during off-peak hours often resolves apparent limit reductions.
Failed generations counting toward quotas surprises many users. Network interruptions, timeout errors, or canceled requests still consume slots from your rolling window. This policy prevents gaming the system but penalizes users with unstable connections. Implementing robust error handling and avoiding repeated attempts for problematic prompts preserves precious generation capacity for successful outputs.
Time zone confusion creates persistent issues for global users. While free tier resets at midnight UTC, the rolling window operates continuously without timezone considerations. Users traveling between time zones or collaborating internationally must carefully track actual generation times rather than assuming consistent daily patterns. Some teams standardize on UTC for all tracking to eliminate confusion.
Account-specific variations add another complexity layer. Users report different actual limits despite identical tier subscriptions. Factors potentially influencing these variations include account age, historical usage patterns, and even content types generated. While OpenAI doesn't officially acknowledge such variations, community evidence suggests the system adapts to individual usage patterns, rewarding consistent, reasonable usage with slightly higher effective limits.
Platform-specific quirks affect users accessing DALL-E 3 through different interfaces. Mobile app users report different limits than web users. API access through third-party integrations may show unexpected behaviors. Even browser choice occasionally impacts generation success rates. Documenting which platform you're using when tracking limits helps identify these patterns and optimize access methods.
Alternative Options and Workarounds
When OpenAI's limits prove constraining, savvy users leverage alternative services to maintain creative flow. The ecosystem around AI image generation has expanded dramatically, offering various options that complement or replace OpenAI's services. Understanding these alternatives enables continuous productivity regardless of primary service limitations.
Bing Image Creator stands out as the most accessible alternative, offering free DALL-E 3 access with only Microsoft account authentication required. While the interface lacks ChatGPT's conversational refinement, the underlying model remains identical. Bing implements a credit system rather than time-based limits, providing 25 weekly "boosts" for faster generation. This different limitation model offers strategic advantages when coordinating with ChatGPT Plus usage.
API alternatives proliferate as demand for programmatic access grows. Services like laozhang.ai aggregate multiple providers, offering discounted rates and simplified integration. These intermediary services handle the complexity of managing multiple upstream providers while presenting unified APIs to developers. For applications requiring scale beyond OpenAI's limits, these aggregators provide essential flexibility. Evaluation criteria should include reliability, data privacy policies, and long-term viability.
Team coordination strategies multiply effective capacity without additional services. Organizations implement various approaches from simple spreadsheet tracking to sophisticated internal tools. Some teams designate "generation specialists" who handle all image creation, concentrating expertise while distributing usage across time. Others implement request queuing systems where team members submit prompts for batch processing during available windows.
Hybrid workflows combining multiple services optimize for different use cases. Initial ideation might use free Bing credits, refinement switches to ChatGPT Plus for conversational iteration, and final production leverages API calls for precise control. This multi-service approach requires managing different interfaces but maximizes available resources. Advanced users maintain prompt libraries that translate between service-specific formats.
Future alternatives continue emerging as the market matures. Open-source models improve rapidly, approaching DALL-E 3 quality for specific use cases. Local generation becomes feasible as hardware advances and models optimize. While these alternatives currently lag in quality or convenience, they represent important fallback options. Maintaining awareness of emerging alternatives ensures continuity when primary services face limitations or policy changes.
Best Practices for Different Use Cases
Content creators face unique challenges balancing creative flow with technical limitations. Successful creators integrate generation windows into natural workflow rhythms rather than forcing artificial schedules. Morning sessions focus on exploration when fresh perspectives aid ideation. Afternoon windows handle refinements when critical evaluation sharpens. This alignment between creative energy and technical availability improves both efficiency and output quality.
Professional photographers using AI for concept development report that limitation awareness improves their traditional skills. Knowing each AI generation consumes limited resources encourages better initial photography and more thoughtful post-processing decisions. The AI becomes a tool for specific enhancements rather than a crutch for poor initial capture. This synergy between traditional and AI techniques produces superior results while respecting resource constraints.
Development teams building AI-powered applications must architect for limitation reality rather than documented promises. Implementing graceful degradation when limits hit, caching strategies to reduce regeneration needs, and user education about system constraints all contribute to successful applications. The most successful apps treat OpenAI as one component in a broader system rather than a single point of failure.
Educational institutions face special challenges with shared resources and diverse user skill levels. Successful implementations create structured workflows where students submit requests through centralized systems. This approach enables fair resource distribution while providing teaching opportunities about prompt engineering and resource management. Some institutions negotiate educational discounts or implement local alternatives for high-volume classroom use.
Marketing agencies generating campaign assets at scale develop sophisticated production pipelines. Batching similar requests optimizes prompt reuse. Implementing approval workflows prevents wasted generations on rejected concepts. Creating style guides that translate brand requirements into effective prompts ensures consistency. These professional practices maximize output quality while minimizing resource consumption.
Individual artists report that embracing limitations sparks creativity. The forced pauses between generation windows provide reflection time that improves artistic development. Many artists describe the rolling window as accidentally beneficial, preventing the "slot machine" mentality of endless regeneration. This philosophical shift from fighting limitations to embracing them as creative constraints yields surprising benefits.
Future of Image Generation Limits
Historical analysis reveals clear trends in OpenAI's limitation evolution. Initial DALL-E 2 limits proved far more restrictive than current offerings. Each major model release accompanied expanded access and refined limitation structures. This pattern suggests continued liberalization as infrastructure scales and competition intensifies. Users should prepare for change while maximizing current allocations.
Competitive pressure from Midjourney, Stable Diffusion, and emerging providers forces OpenAI toward more generous limits. As alternative services offer unlimited or high-volume plans, OpenAI must balance revenue optimization with market retention. The rolling window system, while technically elegant, may yield to simpler models if user friction drives platform switching. Market dynamics suggest movement toward usage-based pricing without complex time restrictions.
Technical infrastructure improvements enable limit expansion. As GPU costs decrease and optimization techniques improve, the marginal cost per image generation drops dramatically. OpenAI's massive funding enables infrastructure investment that should translate to user benefits. However, the pace of demand growth may outstrip infrastructure expansion, maintaining some form of limitations for resource allocation.
Regulatory considerations may influence future limit structures. As AI generation capabilities improve, concerns about misuse grow. Limitations serve not just technical but policy purposes, preventing mass generation of problematic content. Future systems might implement content-aware limitations or require identity verification for higher tiers. Balancing access with responsibility remains an ongoing challenge.
User behavior adaptation continues evolving alongside system changes. Early adopters who mastered the rolling window system developed valuable skills in resource management and strategic planning. These meta-skills transfer across platforms and limitation models. Future users will likely face different constraints but benefit from understanding fundamental resource optimization principles.
Preparing for change requires building flexible workflows independent of specific limitation models. Maintaining multi-platform capabilities, developing efficient prompt engineering skills, and creating robust tracking systems all provide resilience against policy modifications. The specific rules will change, but the need for strategic resource management remains constant in the AI generation landscape.
Quick Reference Guide
Understanding OpenAI's image generation limits requires quick access to key information during active work sessions. This reference section provides essential formulas, calculations, and decision trees for immediate application. Bookmark this section for rapid consultation when planning generation sessions or troubleshooting limit issues.
Rolling Window Calculation Formula: Next Available Slot = Generation Time + 3 Hours. For multiple generations, track each separately. Available Capacity = 50 - (Images generated in past 180 minutes). This simple math underlies the entire system, yet many users never explicitly calculate their availability windows.
Tier Quick Reference: Free: 2/day, midnight UTC reset. Plus: 50/3hr rolling, 200/day max. Pro: Enhanced limits, details vary. API Free: 3/minute typical. API Paid: 7-15/minute typical, tier dependent. These numbers represent practical experience rather than official documentation, providing realistic planning baselines.
Reset Time Cheat Sheet: Free tier: 00:00 UTC daily. ChatGPT Plus: No fixed reset, continuous 3-hour windows. API: Per-minute reset, immediate availability. Pro: Rapid cycling, specifics undocumented. Understanding which model applies to your tier eliminates confusion and enables accurate planning.
Emergency Alternatives Priority: 1) Bing Image Creator (free, Microsoft account). 2) API calls (pay-per-use). 3) Team member accounts (coordinate usage). 4) Wait for rolling window (track timestamps). 5) Third-party services like laozhang.ai for discounted API access. Having this hierarchy prepared prevents creative interruption when limits hit unexpectedly.
Common Error Messages Decoded: "You've reached your limit" = Rolling window exhausted. "Daily maximum reached" = 200 image cap hit. "Too many requests" = API rate limit. "Service temporarily unavailable" = System overload. "Generation failed" = Still counts toward limit. Understanding these messages enables appropriate responses rather than futile retries.
Conclusion
Mastering OpenAI's image generation limit reset time transforms a frustrating constraint into a manageable aspect of your creative workflow. The rolling window system, while initially confusing, rewards users who understand its continuous nature and plan accordingly. By implementing tracking systems, optimizing generation timing, and leveraging alternative services, you can maintain consistent access to AI image generation throughout your workday.
The key insights worth remembering: there is no fixed reset time to wait for with ChatGPT Plus—each image independently exits your quota after three hours. Free tier users face traditional daily resets at midnight UTC. API limits operate on per-minute calculations with immediate availability. These fundamental differences drive entirely different optimization strategies for each tier.
Successful users don't fight the system but align their workflows with its design. Distributing generations across time maintains constant availability. Tracking timestamps enables predictive planning. Understanding actual versus documented limits prevents architectural mistakes. These practices transform limitation management from reactive frustration to proactive optimization.
Looking forward, OpenAI's limits will likely continue evolving as infrastructure scales and competition intensifies. Building flexible workflows that adapt to changing constraints ensures continuity regardless of policy modifications. The specific numbers may change, but the principles of resource optimization remain valuable across platforms and limitation models.
For developers and power users seeking additional capacity, exploring API alternatives like laozhang.ai can provide cost-effective solutions when OpenAI's limits prove constraining. The ecosystem around AI image generation continues expanding, offering options for every use case and budget. Maintaining awareness of these alternatives ensures creative flow never stops, regardless of primary service limitations.
Transform your understanding of OpenAI's image generation limits from obstacle to opportunity. Start tracking your usage today, implement distribution strategies, and watch your effective capacity multiply. The rolling window rewards those who work with its rhythm—master the system, and you'll never unexpectedly hit limits again.