ByteDance LatentSync is an official open-source lip-sync model, but it is not one single product route. If you need control over code, checkpoints, and sensitive face or voice files, start with the ByteDance GitHub repo and Hugging Face weights; if you need no-GPU execution, use a hosted API only after checking that provider's billing, limits, and upload policy.
The route choice is mostly practical: v1.5 is the safer local stop when you are near an 8 GB VRAM ceiling, v1.6 is the higher-quality path when you can handle about 18 GB VRAM, and playground pages belong in low-risk testing until they prove their source and file handling. Keep the official sources separate from third-party routes so you can choose where to run LatentSync before you upload anything.
Choose the route before you run LatentSync
The fastest safe answer is to pick the execution owner first. LatentSync is the model family; the repo, checkpoints, hosted APIs, and browser playgrounds are different contracts around that model.
| Route | Use it when | First check | Do not assume |
|---|---|---|---|
| Official source | You need source control, reproducibility, or privacy | GitHub bytedance/LatentSync, Hugging Face ByteDance/LatentSync-1.6, and arXiv 2412.09262 | That a wrapper ranked above the repo is official |
| Local run | You can run the model on your own GPU and manage files yourself | VRAM, checkpoint version, setup script, Gradio or CLI path | That v1.6 is best for every machine |
| Hosted API | You want no-GPU execution and can accept provider terms | Provider fields, billing owner, input limits, retention, support | That fal or Replicate is a ByteDance-managed API |
| Playground | You only need a low-risk test | Model source, upload policy, operator identity | That a free upload box is safe for real face or voice data |
This route-first split matters because each failure is debugged in a different place. A local install failure belongs to the repo, Python environment, checkpoints, GPU memory, and input files. A hosted API failure belongs to the provider namespace, queue behavior, pricing, file upload contract, and response schema. A playground failure might not be diagnosable at all if the operator does not disclose model source or file handling.
What LatentSync is and what it is not
LatentSync is a lip-sync model, not a general text-to-video generator. The practical input shape is a source video plus target audio, and the job is to align the visible mouth movement with that audio while preserving the face and motion context as much as the model allows.
The official project describes LatentSync as "Taming Stable Diffusion for Lip Sync" and links the implementation to the paper 2412.09262. The method is based on audio-conditioned latent diffusion, with Whisper-derived audio embeddings, U-Net cross-attention, SyncNet-style supervision, and temporal consistency work through StableSyncNet and TREPA. Those details matter most when you are deciding whether this is the right model class. If the job is full-scene generation, character animation from text, or image-to-video motion, a general video model is a different route.
The model boundary also changes safety review. A lip-sync workflow usually handles face video and voice audio together. Those files can identify a person, imply consent, and create rights questions even when the model works technically. Treat the privacy and permission checks as part of the route choice, not as a legal footnote at the end.
Verify the official source before trusting a wrapper
The official source map has three durable anchors: the ByteDance GitHub repository, the ByteDance Hugging Face checkpoint repos, and the arXiv paper. Start there when you need facts that affect installation, model version, checkpoint files, or implementation claims.
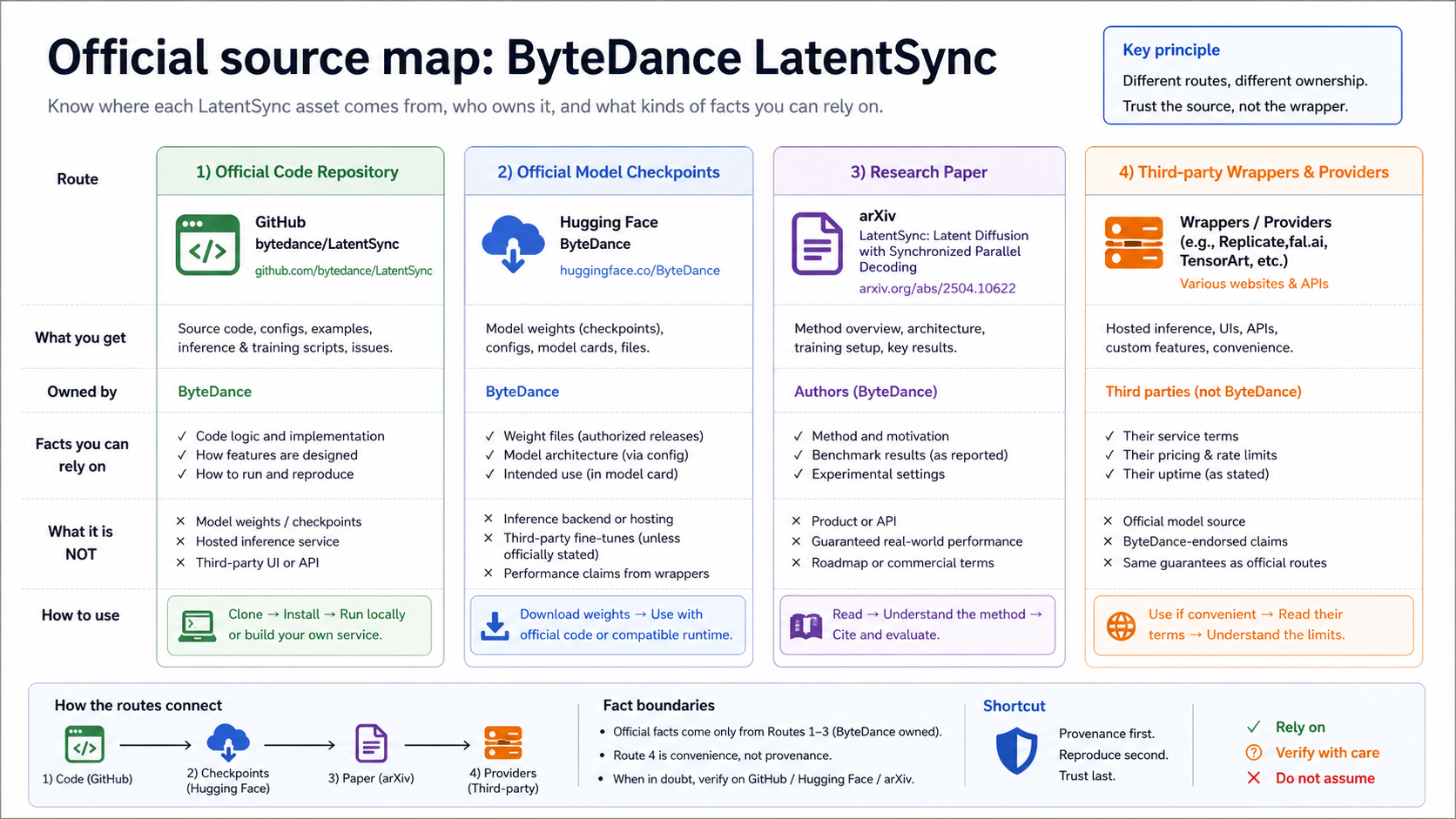
The GitHub repository bytedance/LatentSync is the source-code anchor. At the May 17, 2026 check, the repository metadata identified ByteDance as the owner, listed Python as the main language, exposed Apache-2.0 license metadata for the repo, and showed no GitHub release objects. That last detail is important: if you are looking for a version, read the README update notes and checkpoint references rather than assuming GitHub Releases is the version source.
Hugging Face is the checkpoint anchor. ByteDance/LatentSync-1.6 exposes model files such as latentsync_unet.pt, stable_syncnet.pt, and whisper/tiny.pt; the older ByteDance/LatentSync repo remains a route to previous weights and community Spaces. The Hugging Face model-card metadata uses openrail++, so do not flatten the licensing story into "the repo is Apache, therefore every model-weight use is Apache." Code license and model/checkpoint license are separate things to verify before commercial deployment.
The arXiv paper is the method anchor. It helps you understand what the model is built to do and why it differs from a generic talking-head wrapper, but it is not an execution route. Use the paper for method boundaries, the GitHub repo for install and code facts, and the provider page only for that provider's hosted behavior.
Choose v1.5 or v1.6 by hardware, not by freshness
The version choice is mostly a hardware and quality tradeoff. The README says LatentSync 1.5 needs at least 8 GB VRAM for inference, while LatentSync 1.6 needs at least 18 GB. That makes v1.5 the practical local route for smaller consumer GPUs and v1.6 the route to test when you can afford the heavier memory requirement.

The README update notes also explain why v1.6 exists: the June 11, 2025 release says it was trained on 512x512 videos to mitigate blur. The March 14, 2025 v1.5 note emphasizes better temporal consistency, stronger Chinese-video performance, and lower stage-two training VRAM. That does not make one version universally "best." It gives you a decision rule.
Use v1.5 when the machine is near the 8 GB floor, when you need a faster local proof, or when the input quality does not justify a heavier run. Use v1.6 when the GPU budget is real, blur reduction matters, and you can tolerate the memory cost. If neither route fits your machine, stop before spending hours on environment fixes and test a provider route with non-sensitive files.
Run locally when control matters
Local execution is the right default when the input files are sensitive, the output needs repeatability, or the team wants to inspect code and checkpoints before production. The official route is not hard to identify: clone the ByteDance repository, prepare the environment, download checkpoints through the setup path, then run either the Gradio app or CLI inference.
The README's local shape is:
bashgit clone https://github.com/bytedance/LatentSync.git cd LatentSync source setup_env.sh python gradio_app.py
For scripted inference, the repo also exposes an ./inference.sh path. Keep the first local run boring: one short source video, one short target audio file, the checkpoint version you actually selected, and a machine you know has enough VRAM. That first run should prove the environment, checkpoint download, input format, and output writing before you add batch processing or long files.
Local control has a cost. You own dependency drift, GPU memory, video/audio preprocessing, file storage, and failed-run cleanup. That is still a good trade when the files are private, when consent is sensitive, or when a provider's terms are not clear enough. It is a poor trade when the task is a one-off demo and the machine is below the practical VRAM floor.
Use hosted APIs when no-GPU execution is worth the provider tradeoff
Hosted APIs are convenience routes, not proof of a ByteDance-managed public LatentSync API. The provider owns the endpoint, billing, queue, storage behavior, support path, and sometimes the exact model implementation.
At the May 17, 2026 check, fal exposes a fal-ai/latentsync route with endpoint https://fal.run/fal-ai/latentsync. Its required inputs are video_url and audio_url, with optional fields such as guidance_scale, seed, and loop_mode. The provider file also listed pricing as \$0.20 for videos up to 40 seconds and \$0.005 per output second after that. Treat that as fal-owned pricing checked on that date, not as a ByteDance price.
Replicate exposes a bytedance/latentsync route with input fields named video and audio, plus guidance_scale and seed, and returns a URI output. Its implementation notes mention mp4 video and audio formats such as mp3, aac, wav, and m4a. Because a stable current price was not verified in the same evidence pass, do not put a Replicate cost number into a production estimate without checking the provider page again.
| Hosted route | Input shape checked | Good for | Production check |
|---|---|---|---|
fal fal-ai/latentsync | video_url, audio_url | quick API call when you can host or supply URLs | price date, URL privacy, max duration, failure billing, retention |
Replicate bytedance/latentsync | video, audio | provider-hosted model call with URI output | current price, queue behavior, file limits, output retention, support |
| Wrapper playground | varies | low-risk manual test | operator identity, model source, deletion policy, account requirement |
The reason to use a hosted route is not that it is more official. The reason is that it moves GPU setup and inference operations to a provider. That is valuable when the file risk is low, the team has no local GPU, and provider terms fit the job. It is not a shortcut around consent, rights, or data handling.
Do the upload and production checks before real face or voice files
The upload decision deserves its own stop rule. A LatentSync input pair can contain a real person's face and a real or synthetic voice. Once those files leave your machine, the question is not only "does the model work?" It is also "who receives the files, how long are they retained, who can access outputs, and what happens when a job fails?"
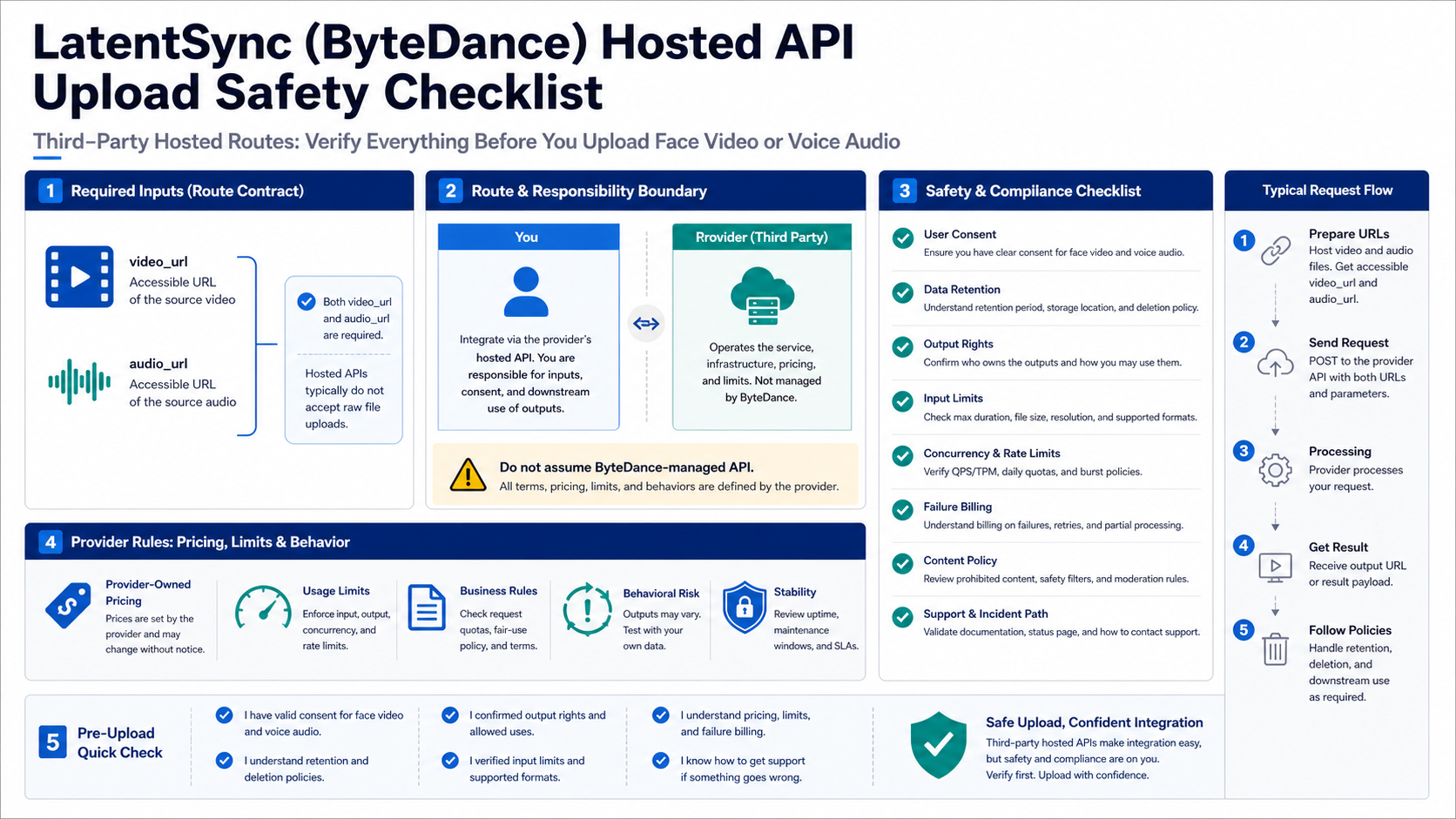
Before uploading anything sensitive, verify six points:
| Check | Why it matters | Stop when |
|---|---|---|
| Consent | Lip-sync can imply speech a person did not say | You do not have permission for the face, voice, or intended use |
| File retention | Hosted routes may store inputs, outputs, logs, or URLs | The provider does not explain deletion or storage behavior |
| Rights and license | Code, weights, input media, and output use can be separate | The route cannot support the commercial or public use you need |
| Input limits | Long videos and unsupported audio formats fail differently | The provider does not state duration, size, or format boundaries |
| Failure billing | Some providers charge for failed or partial jobs | Billing behavior is unclear for retries and failed outputs |
| Support path | Production failures need a human or documented escalation route | There is no issue tracker, support channel, or incident path |
For internal experiments, use synthetic or consent-cleared media first. For client work, record the route owner, model version, input source, consent basis, output path, and deletion policy. Those notes are more useful than a screenshot of a successful demo when the workflow moves from test to production.
A practical route recommendation
Start with the official repo and checkpoint pages if you are doing engineering work. That gives you the cleanest source of truth for versions, hardware, commands, and method boundary. Move to a hosted API only after the local hardware cost or operational burden is clearly higher than the provider trust cost. Use playgrounds for exploration, not as the first destination for valuable face or voice files.
The decision can be compact:
| If your priority is... | Start here | Why |
|---|---|---|
| Official proof | GitHub plus Hugging Face | It separates ByteDance-owned project facts from wrapper claims |
| Private files | Local v1.5 or v1.6 | Inputs stay in your environment if you manage storage correctly |
| No GPU | Hosted API | Provider handles inference, but provider owns billing and file terms |
| Fast curiosity | Playground with dummy media | It is enough to see the workflow shape, not enough for production |
| Production reliability | Local or provider route with written terms | You need logs, limits, retention, retries, and support before scale |
That recommendation intentionally avoids a universal winner. LatentSync's main question is not "which link is first?" It is "which execution contract matches the files, hardware, and risk in front of you?"
FAQ
Is LatentSync officially from ByteDance?
Yes. The official open-source project is the GitHub repository bytedance/LatentSync, and ByteDance also maintains Hugging Face checkpoint routes. Wrapper sites and provider pages can still be useful, but they should be treated as separate route owners unless they prove a formal ByteDance relationship.
Does ByteDance offer an official LatentSync API?
No public ByteDance-managed LatentSync API route was verified in the current evidence set. Hosted routes such as fal and Replicate are third-party provider contracts around LatentSync or implementations of it, so describe them as hosted API routes rather than an official LatentSync API.
Which version should I use locally?
Use the README's VRAM split as the first filter. LatentSync 1.5 is the safer local choice near an 8 GB VRAM ceiling. LatentSync 1.6 is the higher-quality route to test when about 18 GB VRAM is available and blur reduction matters enough to justify the heavier run.
Are the GitHub code and Hugging Face weights under the same license?
Do not assume that. The GitHub repository exposes Apache-2.0 license metadata for the code, while Hugging Face model-card metadata exposes openrail++ for model weights. Check both before commercial deployment, redistribution, or customer-facing use.
Can I use a free playground for real videos?
Use playgrounds only for low-risk tests unless the operator clearly proves model source, file retention, deletion policy, account handling, output rights, and support. A free upload path is not automatically safe for a real person's face or voice.
What should I log for production?
Record the route owner, model version or provider model name, input file source, consent basis, upload destination, output URI or file path, failure or retry reason, billing owner, and deletion or retention policy. Those fields make later debugging and rights review possible.