![GPT-Image-1 Tier System Guide: Understanding and Optimizing Rate Limits [2025 Complete Analysis]](/posts/en/gpt-image-1-tier-system-guide/img/cover.png)
Since its release in April 2025, OpenAI's GPT-Image-1 has established itself as the industry's leading image generation model, offering unprecedented text rendering, photorealistic outputs, and creative capabilities. However, developers worldwide have encountered a complex and often confusing tier-based rate limiting system that can significantly impact implementation plans. This comprehensive guide analyzes the complete GPT-Image-1 tier structure, explains the rationale behind these limitations, and provides practical strategies to optimize your usage.
Understanding GPT-Image-1's Tiered Access System
Unlike previous OpenAI models, GPT-Image-1 employs a sophisticated tier-based access system designed to balance infrastructure capacity with developer demand. This section explains the complete tier structure as of May 2025.
The Current Tier Structure Explained
OpenAI has implemented a multi-level tier system for GPT-Image-1 that determines your access level, rate limits, and capabilities:
javascript// GPT-Image-1 Tier Structure (May 2025) const tierSystem = { "Free Tier": { access: "None", rateLimit: "0 RPM", tokenLimit: "0 TPM" }, "Tier 1": { access: "Limited", requirements: "\$5+ lifetime spend", rateLimit: "6 RPM", tokenLimit: "250,000 TPM" }, "Tier 2": { access: "Standard", requirements: "\$50+ lifetime spend + 7+ days account age", rateLimit: "15 RPM", tokenLimit: "500,000 TPM" }, "Tier 3": { access: "Enhanced", requirements: "\$500+ lifetime spend + 30+ days account age", rateLimit: "25 RPM", tokenLimit: "1,000,000 TPM" }, "Enterprise": { access: "Full", requirements: "Custom contract", rateLimit: "60+ RPM", tokenLimit: "Custom TPM" } };
Common Rate Limit Error Messages Explained
When encountering rate limits with GPT-Image-1, you may receive various error messages depending on which limit you've reached:
-
429 Rate Limit Exceeded
json{ "error": { "message": "Rate limit exceeded for gpt-image-1 requests per minute (RPM). Limit: 6, current: 7", "type": "rate_limit_exceeded", "param": null, "code": "rate_limit_exceeded" } } -
429 Token Limit Exceeded
json{ "error": { "message": "Token limit exceeded for gpt-image-1 per minute (TPM). Limit: 250000, current: 250183", "type": "tokens_limit_exceeded", "param": null, "code": "tokens_limit_exceeded" } } -
403 Access Denied Error
json{ "error": { "message": "You are not authorized to use gpt-image-1. Please upgrade to Tier 1 by spending at least \$5 on API usage.", "type": "insufficient_quota", "param": null, "code": "insufficient_quota" } }
Each of these errors has a different root cause and requires a specific approach to resolve.
Why Some Users Experience "No Limit" Errors
A particularly confusing issue reported by many developers is receiving rate limit errors showing "retry after 0.0 seconds":
json{ "error": { "message": "You've exceeded the rate limit, please slow down and try again after 0.0 seconds", "type": "rate_limit_exceeded", "param": null, "code": "rate_limit_exceeded" } }
This seemingly contradictory message indicates a tier access issue rather than an actual rate limit—your account lacks proper access to the model despite having sufficient funds. This typically means you haven't met all tier requirements yet (both spending and account age requirements).
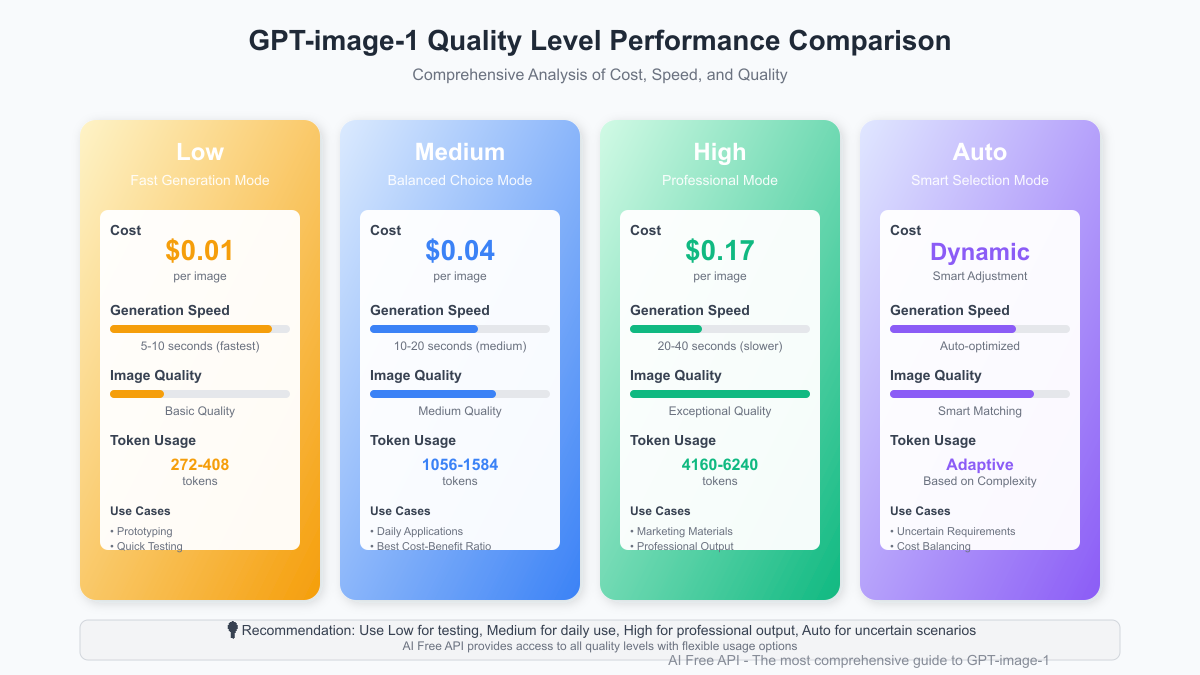
Understanding TPM vs. RPM: The Dual Limit System
GPT-Image-1 employs a dual-limit system that restricts both your Requests Per Minute (RPM) and Tokens Per Minute (TPM):
Requests Per Minute (RPM)
The RPM limit controls how many separate API calls you can make within a 60-second rolling window:
- Tier 1: 6 RPM (one request every 10 seconds)
- Tier 2: 15 RPM (one request every 4 seconds)
- Tier 3: 25 RPM (one request every 2.4 seconds)
RPM limits apply regardless of request size or complexity.
Tokens Per Minute (TPM)
The TPM limit controls the total computational resources available to you:
- Tier 1: 250,000 TPM
- Tier 2: 500,000 TPM
- Tier 3: 1,000,000 TPM
For perspective, a typical image generation request consuming approximately 12,000 tokens means:
- Tier 1 users can generate ~20 complex images per minute (if spread perfectly)
- Tier 2 users can generate ~40 complex images per minute
- Tier 3 users can generate ~80 complex images per minute
However, the RPM limits mean you'll hit the request cap long before reaching token limits in most cases.
The Unexpected "Rate Limit Without Generation" Problem
Many developers report receiving rate limit errors without generating a single image. This peculiar issue stems from OpenAI's verification system:
Root Causes:
- Account Verification Status: Some regions require additional verification steps
- Limited Initial Access: New accounts may have temporary restrictions
- Spending Pattern Analysis: OpenAI's fraud protection system examines spending history
- Regional Restrictions: Some regions have additional verification requirements
Technical Explanation:
When you make your first GPT-Image-1 request, OpenAI performs several behind-the-scenes checks:
python# Pseudocode for OpenAI's verification process def verify_image_request(user, request): # Check if model is available in user's region if not is_model_available_in_region(user.region, "gpt-image-1"): return Error("Model not available in your region") # Check tier access if not user.has_tier_access("gpt-image-1"): # Check spending requirement if user.lifetime_spend < 5.0: return Error("Insufficient spending") # Check account age requirement (Tier 2+) if user.requesting_tier_2_access and user.account_age_days < 7: return Error("Account too new for requested tier") # Check for verification status if not user.is_verified(): return Error("Account requires verification") # All checks passed return process_image_request(request)
This multi-stage verification process explains why you might hit limits before generating a single image.
5 Strategies for Optimizing GPT-Image-1 Access and Usage
Now that we understand the tier system's structure, let's explore practical strategies to optimize your access and usage.
Strategy 1: Strategic Tier Progression
Most developers should follow a deliberate tier progression path:
mermaidgraph TD A[New Account] --> B[Spend \$5 on other models] B --> C[Gain Tier 1 Access] C --> D[Implement rate limiting] D --> E[Continue normal usage for 7 days] E --> F[Spend additional \$45] F --> G[Gain Tier 2 Access] G --> H[Scale operations gradually] H --> I[Monitor usage patterns] I --> J[Evaluate need for Tier 3]
This progression allows your account to mature naturally while establishing a usage history that helps avoid verification issues.
Strategy 2: API Proxy Services for Immediate Access
For immediate, unrestricted access, third-party API proxy services provide a valuable alternative:
LaoZhang.ai Implementation
pythonimport openai # Configure client to use proxy service client = openai.OpenAI( api_key="YOUR_LAOZHANG_API_KEY", base_url="https://api.laozhang.ai/v1" ) # Generate image without tier restrictions response = client.chat.completions.create( model="gpt-image-1", # Same model name as OpenAI messages=[{ "role": "user", "content": "Generate a photorealistic image of a modern smart home with integrated AI assistants" }] ) # Access image URL image_url = response.choices[0].message.content
Benefits of this approach:
- Immediate access without tier restrictions
- Cost savings (typically 75-80% lower than direct API)
- No verification requirements
- Higher rate limits
Strategy 3: Intelligent Rate Limit Management
For direct API users, implementing intelligent rate limiting is essential:
pythonimport asyncio import time from collections import deque import openai class AdaptiveRateLimiter: def __init__(self, max_rpm=5, safety_factor=0.8): self.max_rpm = max_rpm self.safety_factor = safety_factor # Stay below limit self.request_times = deque(maxlen=max_rpm) self.lock = asyncio.Lock() async def wait_if_needed(self): """Wait if we're approaching rate limits""" async with self.lock: now = time.time() # Clean old requests while self.request_times and now - self.request_times[0] > 60: self.request_times.popleft() # Calculate safe request count safe_request_count = int(self.max_rpm * self.safety_factor) # If too many recent requests, wait if len(self.request_times) >= safe_request_count: # Calculate wait time based on oldest request wait_time = 60 - (now - self.request_times[0]) if wait_time > 0: await asyncio.sleep(wait_time) # Add current request time and proceed self.request_times.append(now) async def execute_with_rate_limiting(self, func, *args, **kwargs): """Execute a function with rate limiting""" await self.wait_if_needed() return await func(*args, **kwargs)
This adaptive limiter ensures you stay within your tier's limits while maximizing throughput.
Strategy 4: Batch Processing and Job Queuing
For applications requiring multiple images, implementing a job queue system dramatically improves efficiency:
pythonimport asyncio import redis from rq import Queue class GPTImageJobQueue: def __init__(self, redis_url="redis://localhost:6379"): self.redis_conn = redis.from_url(redis_url) self.queue = Queue(connection=self.redis_conn) self.rate_limiter = AdaptiveRateLimiter() def enqueue_image_job(self, prompt, callback_url=None): """Add image generation job to queue""" job = self.queue.enqueue( 'worker.generate_image', prompt=prompt, callback_url=callback_url, job_id=f"img_{time.time()}_{hash(prompt)}" ) return job.id def get_job_status(self, job_id): """Check status of a job""" job = self.queue.fetch_job(job_id) if not job: return {"status": "not_found"} return { "status": job.get_status(), "result": job.result, "enqueued_at": job.enqueued_at, "started_at": job.started_at, "ended_at": job.ended_at }
This system allows your application to accept unlimited requests while processing them at a rate that complies with your tier's limits.
Strategy 5: Geographic Distribution and Region Optimization
GPT-Image-1 availability and rate limits vary by region. By strategically distributing requests across regions, you can increase overall throughput:
pythonclass RegionOptimizer: def __init__(self): self.regions = { "us-east": { "endpoint": "https://api.openai.com/v1", "api_key": "US_EAST_API_KEY", "availability": 0.98, # Availability score "latency": 120 # Average ms response time }, "eu-west": { "endpoint": "https://eu.api.openai.com/v1", "api_key": "EU_WEST_API_KEY", "availability": 0.95, "latency": 150 }, "asia": { "endpoint": "https://api.laozhang.ai/v1", # Proxy for Asia "api_key": "ASIA_PROXY_KEY", "availability": 0.99, "latency": 180 } } self.clients = { region: openai.OpenAI( api_key=config["api_key"], base_url=config["endpoint"] ) for region, config in self.regions.items() } def select_optimal_region(self): """Select best region based on availability and performance""" best_score = 0 best_region = None for region, config in self.regions.items(): # Calculate score based on availability and latency score = config["availability"] * (1000 / config["latency"]) if score > best_score: best_score = score best_region = region return best_region async def generate_with_optimal_region(self, prompt): """Generate image using optimal region""" region = self.select_optimal_region() client = self.clients[region] try: return client.chat.completions.create( model="gpt-image-1", messages=[{"role": "user", "content": prompt}] ) except openai.RateLimitError: # Try next best region del self.regions[region] # Temporarily remove region from options if self.regions: return await self.generate_with_optimal_region(prompt) else: raise Exception("All regions exhausted")
This approach not only increases your effective rate limits but also improves reliability through redundancy.

Common Scenarios and Solutions
Scenario 1: Immediate Access Needed for Production
Challenge: You need immediate GPT-Image-1 access for a production application launching next week.
Solution: Implement a multi-provider strategy:
- Set up LaoZhang.ai for immediate, reliable access
- Simultaneously begin the tier progression process with OpenAI
- Implement a fallback system that tries OpenAI first, then falls back to the proxy
- Gradually transition to direct API as your tier level increases
This approach ensures immediate access while building toward long-term direct integration.
Scenario 2: High-Volume Batch Processing
Challenge: Your application needs to generate 10,000+ images daily.
Solution: Implement a distributed processing system:
- Distribute requests across multiple regions and providers
- Use a persistent queue system with rate-aware workers
- Implement intelligent caching for similar requests
- Consider a hybrid approach using multiple tiers:
- Tier 3 direct API for priority jobs
- Proxy services for overflow capacity
- Azure OpenAI for enterprise workloads
Scenario 3: Cost Optimization for Startups
Challenge: You need to minimize costs while maintaining reliable access.
Solution: Strategic cost management:
- Use LaoZhang.ai's $0.01/image rate for 75% cost reduction
- Implement aggressive caching for common requests
- Optimize prompt engineering to achieve results with fewer generations
- Use preview-quality images during development, full quality for production
Troubleshooting GPT-Image-1 Rate Limit Issues
Error: "Rate limit exceeded without even generating a single image"
This common error occurs when your account hasn't fully met all tier requirements:
- Verify spending: Check that you've spent at least $5 lifetime on your account
- Check account age: Some regions enforce minimum account age requirements
- Confirm organization verification: Ensure your organization is fully verified
- Review payment history: Recent payments may not be immediately reflected
- Contact support: For persistently verified accounts, contact OpenAI support
Error: "Rate limit exceeded, please try again after 7 minutes"
This error typically affects ChatGPT Plus users trying to generate images through the UI:
The current limit is set so that you can only generate one new image every 7 minutes – regardless of how many you request at once.
This is a separate limitation system for the consumer product and doesn't affect API users directly. For programmatic access, follow the tier system described earlier.
Future-Proofing Your Implementation
OpenAI's tier system continues to evolve. According to recent developer discussions, several changes are anticipated in Q3-Q4 2025:
- Granular permissions: More specific control over image generation capabilities
- Usage-based tiers: Dynamic limits based on historical usage patterns
- Regional availability expansion: More regions with direct access
- Enterprise features: Additional controls for business customers
To future-proof your implementation:
pythonclass GPTImageClient: def __init__(self): # Initialize with fallbacks and alternatives self.providers = { "openai_direct": self._setup_openai_direct(), "laozhang_proxy": self._setup_laozhang_proxy(), "azure_openai": self._setup_azure_openai() } # Feature detection and capability mapping self.capabilities = self._detect_capabilities() def _detect_capabilities(self): """Detect available capabilities across providers""" capabilities = {} for provider_name, client in self.providers.items(): try: # Test basic image generation test_response = client.chat.completions.create( model="gpt-image-1", messages=[{"role": "user", "content": "Generate a test image"}], max_tokens=100 ) capabilities[provider_name] = { "available": True, "features": self._extract_features(test_response) } except Exception as e: capabilities[provider_name] = { "available": False, "error": str(e) } return capabilities def generate_image_with_fallbacks(self, prompt, style=None): """Generate image using best available provider""" # Sort providers by preference and availability sorted_providers = sorted( [(name, config) for name, config in self.capabilities.items() if config["available"]], key=lambda x: self._calculate_provider_score(x[0]) ) # Try each provider in sequence for provider_name, _ in sorted_providers: try: client = self.providers[provider_name] response = client.chat.completions.create( model="gpt-image-1", messages=[{"role": "user", "content": prompt}] ) return { "provider": provider_name, "response": response } except Exception as e: continue raise Exception("All providers failed")
This flexible architecture allows your system to adapt as OpenAI modifies the tier system and introduces new capabilities.
Conclusion
OpenAI's GPT-Image-1 represents a significant leap forward in AI image generation, but its complex tier system creates challenges for developers. By understanding the nuances of rate limits, implementing strategic access patterns, and utilizing tools like LaoZhang.ai's proxy service, you can ensure reliable access while optimizing costs.
The strategies outlined in this guide provide a comprehensive approach to navigating GPT-Image-1's tier system, from immediate access solutions to long-term optimization techniques. As OpenAI continues to refine its access model, the principles of redundancy, intelligent rate management, and strategic tier progression will remain valuable for developers seeking to leverage this powerful technology.
For the most seamless experience with GPT-Image-1, sign up for LaoZhang.ai today at https://api.laozhang.ai/register/ and gain immediate access while building your long-term implementation strategy.
Last updated: May 28, 2025 This guide is regularly updated as OpenAI modifies its tier system and rate limits.