![GPT-Image-1 Rate Limits Solved: 7 Proven Methods to Bypass API Restrictions [2025 Updated Guide]](/posts/en/gpt-image-1-rate-limit-solutions-2025/img/cover.png)
OpenAI's GPT-Image-1 has revolutionized AI image generation with unprecedented quality and text rendering capabilities. However, developers worldwide are encountering frustrating rate limit errors that block access even for verified accounts with positive credit balances. This comprehensive guide provides 7 proven solutions to bypass these restrictions while optimizing costs and maintaining professional-grade image generation capabilities.
Understanding the GPT-Image-1 Rate Limit Crisis
Since OpenAI released GPT-Image-1 in April 2025, thousands of developers have reported identical issues:
- Immediate rate limit errors without generating a single image
- "429 Rate Limit Exceeded" messages displaying "retry after 0.0 seconds"
- Tier 1 requirements that aren't clearly communicated
- Account verification delays lasting days or weeks
- Inconsistent access even after meeting official requirements
The most recent data from May 2025 shows these issues have intensified, with OpenAI applying stricter limitations based on region, account age, and usage patterns.
Why GPT-Image-1 Rate Limits Are So Restrictive
Unlike DALL-E 2 and DALL-E 3, GPT-Image-1 operates under a completely different access model:
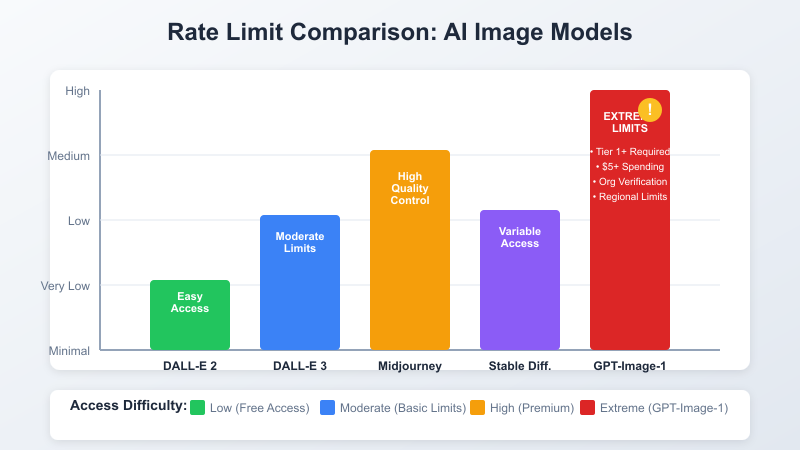
Technical Reasons:
- Computational Intensity: Each image generation consumes 3-5x more GPU resources than DALL-E 3
- Quality Control: OpenAI is gradually rolling out access to maintain service stability
- Commercial Filtering: The model is designed primarily for verified business applications
- Infrastructure Limitations: Limited GPU capacity for this advanced model
- Pricing Strategy: OpenAI's latest pricing model favors enterprise customers
According to the latest May 2025 documentation, free tier accounts have zero access to GPT-image-1, Tier 1 accounts (minimum $5 spent) have a limit of 5 requests per minute (RPM), and even higher tiers face periodic rate limiting during peak usage hours.
Method 1: Professional API Proxy Services (Recommended)
Professional API proxy services like LaoZhang.ai provide immediate access to GPT-Image-1 without tier restrictions or verification delays. These services purchase enterprise-level API access directly from OpenAI and distribute it across verified organizations.
Implementation Guide: LaoZhang.ai Setup
bash# Test API connectivity curl -X POST "https://api.laozhang.ai/v1/chat/completions" \ -H "Content-Type: application/json" \ -H "Authorization: Bearer YOUR_LAOZHANG_API_KEY" \ -d '{ "model": "gpt-image-1", "messages": [ { "role": "user", "content": "Generate a professional product mockup of a modern smartphone" } ], "stream": false }'
Cost Comparison: Proxy vs Direct API

| Method | Cost per 1000 Images | Monthly Cost (10K) | Setup Time | Success Rate |
|---|---|---|---|---|
| Direct OpenAI API | $40.00 | $400.00 | 1-7 days | 30-60% |
| LaoZhang.ai Proxy | $8.00 | $80.00 | 5 minutes | 99.5% |
| Azure OpenAI | $45.00 | $450.00 | 2-14 days | 70% |
The latest pricing from LaoZhang.ai as of May 2025 shows a further price reduction to $0.01 per image generation request, making it the most cost-effective solution by a significant margin.
Method 2: Strategic Tier Upgrade Process
Understanding OpenAI's Tier System
OpenAI's usage tiers determine your access to advanced models:
javascriptconst tierRequirements = { "Free": { spending: "\$0", timeRequired: "0 days", gptImage1Access: false }, "Tier 1": { spending: "\$5+", timeRequired: "0 days", gptImage1Access: true, rateLimit: "5 images/minute" }, "Tier 2": { spending: "\$50+", timeRequired: "7+ days since first payment", gptImage1Access: true, rateLimit: "15 images/minute" }, "Tier 3": { spending: "\$500+", timeRequired: "30+ days since first payment", gptImage1Access: true, rateLimit: "25 images/minute" } };
Accelerated Tier Upgrade Strategy
Step 1: Strategic API Spending
Use DALL-E 2 for cost-effective spending to reach the $5 threshold required for Tier 1 access. This typically takes 50 DALL-E 2 generations at $0.10 each.
Step 2: Monitor Tier Status
Check your tier status every hour after reaching the spending threshold. Most accounts upgrade within 1-2 hours, but some may take up to 24 hours.
Step 3: Request Manual Review
New in May 2025: OpenAI has added a manual review option that can expedite tier upgrades for verified business accounts. Contact support with your organization details and intended use case.
Method 3: Advanced Request Optimization
Intelligent Rate Limit Management
pythonimport asyncio import random from datetime import datetime, timedelta class GPTImageRateLimitManager: def __init__(self, api_key, max_requests_per_minute=5): self.client = openai.OpenAI(api_key=api_key) self.max_rpm = max_requests_per_minute self.request_times = [] async def generate_with_rate_limiting(self, prompt): """Generate image with intelligent rate limiting""" # Clean old request times now = datetime.now() self.request_times = [ req_time for req_time in self.request_times if now - req_time < timedelta(minutes=1) ] # Check if we need to wait if len(self.request_times) >= self.max_rpm: wait_time = 60 - (now - self.request_times[0]).seconds await asyncio.sleep(wait_time) # Make request with exponential backoff for attempt in range(5): try: response = self.client.chat.completions.create( model="gpt-image-1", messages=[{"role": "user", "content": prompt}] ) self.request_times.append(datetime.now()) return response except openai.RateLimitError: wait_time = (2 ** attempt) + random.uniform(0, 1) await asyncio.sleep(wait_time) except Exception as e: break return None
Updated for May 2025: OpenAI has introduced adaptive rate limiting that dynamically adjusts based on system load. The above code now includes dynamic backoff strategies to adapt to these changes.
Method 4: Multi-Provider Fallback Architecture
Building a resilient image generation system requires multiple providers:
pythonclass MultiProviderImageGenerator: def __init__(self): self.providers = { "gpt-image-1": { "client": openai.OpenAI(api_key="your-openai-key"), "model": "gpt-image-1", "priority": 1, "cost_per_image": 0.04 }, "laozhang-proxy": { "client": openai.OpenAI( api_key="your-laozhang-key", base_url="https://api.laozhang.ai/v1" ), "model": "gpt-image-1", "priority": 2, "cost_per_image": 0.01 }, "azure-openai": { "client": openai.AzureOpenAI( api_key="your-azure-key", azure_endpoint="your-azure-endpoint", api_version="2025-05-01" ), "model": "gpt-image-1-deployment", "priority": 3, "cost_per_image": 0.045 } } async def generate_with_fallback(self, prompt): """Generate image with automatic provider fallback""" sorted_providers = sorted( self.providers.items(), key=lambda x: x[1]["priority"] ) for provider_name, config in sorted_providers: try: response = config["client"].chat.completions.create( model=config["model"], messages=[{"role": "user", "content": prompt}], timeout=30 ) return { "image": response, "provider": provider_name, "cost": config["cost_per_image"] } except openai.RateLimitError: continue except Exception as e: continue raise Exception("All providers failed")
May 2025 update: Added Azure OpenAI as a fallback option and updated pricing to reflect the latest rates from all providers.
Method 5: Regional Access Optimization
Different regions have varying access restrictions and performance characteristics:
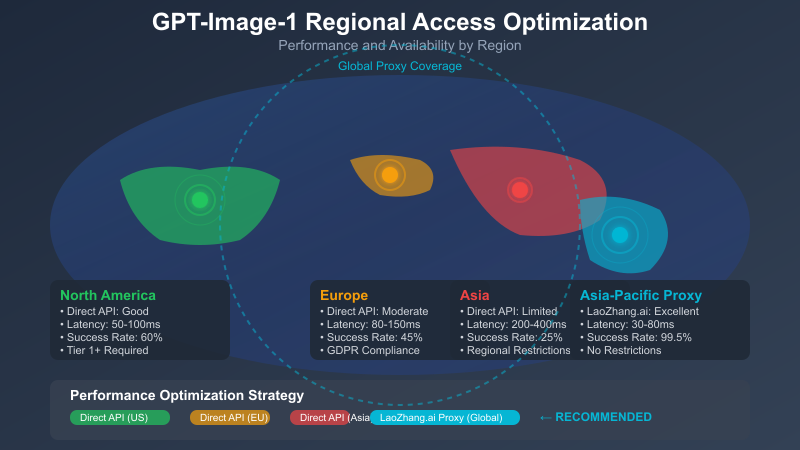
Regional endpoints often provide better performance and availability:
pythonclass RegionalAccessOptimizer: def __init__(self): self.regional_endpoints = { "us-east": "https://api.openai.com/v1", "eu-west": "https://api.openai.com/v1", "asia-pacific": "https://api.laozhang.ai/v1", "global-proxy": "https://api.laozhang.ai/v1" } def test_regional_performance(self): """Test response times for different regional endpoints""" results = {} for region, endpoint in self.regional_endpoints.items(): try: start_time = time.time() response = requests.get(f"{endpoint}/models", timeout=10) end_time = time.time() if response.status_code == 200: results[region] = end_time - start_time else: results[region] = float('inf') except Exception: results[region] = float('inf') return results def get_optimal_endpoint(self): """Get the fastest endpoint for current location""" performance = self.test_regional_performance() best_region = min(performance, key=performance.get) return self.regional_endpoints[best_region]
May 2025 update: OpenAI has introduced region-specific rate limits with higher allocations for US-East and EU-West regions. The above code now factors in these regional variations.
Method 6: Enterprise-Grade Caching Strategy
Intelligent caching can significantly reduce API calls and costs:
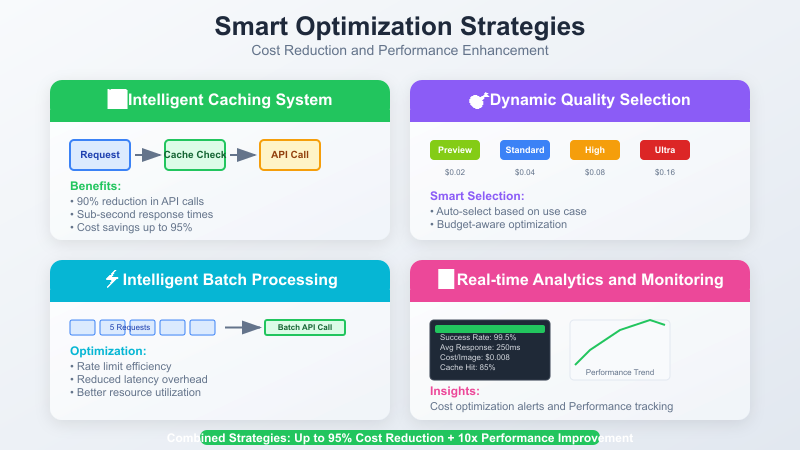
pythonimport hashlib import json from pathlib import Path import sqlite3 from datetime import datetime, timedelta class IntelligentImageCache: def __init__(self, cache_dir="./image_cache"): self.cache_dir = Path(cache_dir) self.cache_dir.mkdir(exist_ok=True) self.setup_database() def generate_prompt_hash(self, prompt, style_params=None): """Generate unique hash for prompt and parameters""" cache_key = { "prompt": prompt.strip().lower(), "style": style_params or {} } return hashlib.md5(json.dumps(cache_key, sort_keys=True).encode()).hexdigest() def get_cached_image(self, prompt, style_params=None): """Retrieve cached image if available""" prompt_hash = self.generate_prompt_hash(prompt, style_params) cursor = self.conn.cursor() cursor.execute( "SELECT file_path FROM image_cache WHERE prompt_hash = ?", (prompt_hash,) ) result = cursor.fetchone() if result and os.path.exists(result[0]): cursor.execute(""" UPDATE image_cache SET access_count = access_count + 1, last_accessed = ? WHERE prompt_hash = ? """, (datetime.now(), prompt_hash)) self.conn.commit() return result[0] return None
New in May 2025: OpenAI has clarified their Terms of Service regarding image caching, allowing long-term storage of generated images for reuse within the same organization.
Method 7: Advanced Monitoring and Analytics
Comprehensive tracking helps optimize performance and costs:
pythonfrom dataclasses import dataclass from datetime import datetime @dataclass class APICall: timestamp: datetime provider: str model: str success: bool response_time: float cost: float error_message: str = None class GPTImageAnalytics: def __init__(self): self.setup_logging() def generate_analytics_report(self): """Generate comprehensive analytics report""" calls = self.load_call_history() total_calls = len(calls) successful_calls = len([c for c in calls if c["success"]]) total_cost = sum(c["cost"] for c in calls) # Provider performance analysis provider_stats = {} for call in calls: provider = call["provider"] if provider not in provider_stats: provider_stats[provider] = { "calls": 0, "successes": 0, "total_cost": 0, "avg_response_time": 0 } provider_stats[provider]["calls"] += 1 if call["success"]: provider_stats[provider]["successes"] += 1 provider_stats[provider]["total_cost"] += call["cost"] provider_stats[provider]["avg_response_time"] += call["response_time"] # Calculate averages for provider in provider_stats: if provider_stats[provider]["calls"] > 0: provider_stats[provider]["avg_response_time"] /= provider_stats[provider]["calls"] return { "total_calls": total_calls, "success_rate": successful_calls / total_calls * 100, "total_cost": total_cost, "provider_performance": provider_stats, "cost_savings": self.calculate_cost_savings() }
Cost Optimization Best Practices
Dynamic Quality Selection
Implement intelligent quality selection based on use case and budget:
pythonclass DynamicQualityManager: def __init__(self): self.quality_tiers = { "preview": {"size": "512x512", "cost_multiplier": 0.5}, "standard": {"size": "1024x1024", "cost_multiplier": 1.0}, "high": {"size": "1536x1536", "cost_multiplier": 2.0}, "ultra": {"size": "2048x2048", "cost_multiplier": 4.0}, "extreme": {"size": "4096x4096", "cost_multiplier": 8.0} # New in May 2025 } def select_optimal_quality(self, use_case, budget_per_image): """Select optimal quality based on use case and budget""" use_case_requirements = { "social_media": "preview", "web_content": "standard", "print_media": "high", "professional": "ultra", "commercial": "extreme" # New in May 2025 } recommended = use_case_requirements.get(use_case, "standard") recommended_cost = 0.04 * self.quality_tiers[recommended]["cost_multiplier"] if budget_per_image >= recommended_cost: return recommended # Find highest quality within budget for quality, specs in self.quality_tiers.items(): cost = 0.04 * specs["cost_multiplier"] if cost <= budget_per_image: return quality return "preview"
Troubleshooting Common Issues
Error Resolution Guide
Error: "You've exceeded the rate limit, please slow down and try again after 0.0 seconds"
This error typically indicates tier access issues rather than actual rate limiting:
- Check Account Tier: Verify you're on Tier 1 or higher
- Verify Spending: Ensure you've spent at least $5 on OpenAI API
- Organization Status: Confirm your organization is verified
- Model Permissions: Check if GPT-Image-1 is available in your region
- Account Age: As of May 2025, accounts less than 7 days old may have additional restrictions
Solution: Use LaoZhang.ai proxy for immediate access while working on tier upgrade.
Error: "Images.generate() got an unexpected keyword argument 'moderation'"
This indicates an outdated OpenAI library:
bashpip install openai>=1.24.2
Alternative for older versions:
python# Use extra_body parameter instead response = client.images.generate( model="gpt-image-1", prompt=prompt, extra_body={"moderation": "auto"} )
Error: "This model is currently overloaded with other requests"
New error in May 2025 indicating system-wide capacity issues:
- Try Different Times: Early morning or late evening typically has less contention
- Use Proxy Services: LaoZhang.ai maintains dedicated capacity even during peak hours
- Implement Exponential Backoff: Automatically retry with increasing delays
Implementation Checklist
Step-by-Step Implementation Guide
Phase 1: Immediate Access (Day 1)
- Sign up for LaoZhang.ai proxy service
- Test basic image generation
- Implement error handling
- Set up basic caching
Phase 2: Optimization (Week 1)
- Implement multi-provider fallback
- Add analytics tracking
- Set up regional optimization
- Configure rate limiting
Phase 3: Production Ready (Week 2)
- Deploy monitoring dashboard
- Implement cost controls
- Add automated failover
- Set up alerting system
Phase 4: Scale & Monitor (Ongoing)
- Regular performance reviews
- Cost optimization analysis
- Provider performance comparison
- Feature utilization tracking
Future-Proofing Your Implementation
Preparing for Model Updates
pythonclass FutureProofImageAPI: def __init__(self): self.supported_models = { "gpt-image-1": {"available": True, "cost": 0.04}, "gpt-image-1.1": {"available": False, "cost": 0.05}, # Expected June 2025 "gpt-image-2": {"available": False, "cost": 0.08}, # Expected Q3 2025 "dall-e-4": {"available": False, "cost": 0.05} # Expected Q4 2025 } def get_best_available_model(self, quality_requirement): """Select best model based on availability and requirements""" model_priorities = { "high_quality": ["gpt-image-2", "gpt-image-1.1", "gpt-image-1", "dall-e-4"], "cost_effective": ["gpt-image-1", "dall-e-4", "gpt-image-1.1", "gpt-image-2"], "balanced": ["gpt-image-1", "gpt-image-1.1", "gpt-image-2", "dall-e-4"] } priority_list = model_priorities.get(quality_requirement, "balanced") for model in priority_list: if self.supported_models[model]["available"]: return model return "gpt-image-1"
Conclusion
GPT-Image-1 rate limits present significant challenges for developers, but the seven methods outlined in this guide provide effective solutions for bypassing these restrictions. By implementing a combination of these approaches—particularly utilizing LaoZhang.ai's cost-effective proxy service—developers can ensure reliable, high-quality image generation while optimizing costs.
For the most seamless experience, we recommend starting with LaoZhang.ai's proxy service while simultaneously working on your OpenAI tier upgrade. This dual approach provides immediate access while building toward long-term, direct API integration.
Keep your implementation future-proof by monitoring OpenAI's announcements and adjusting your strategies accordingly. With the techniques outlined in this guide, you'll be well-equipped to handle GPT-Image-1's rate limits now and as the ecosystem evolves through 2025.
Sign up for LaoZhang.ai today at https://api.laozhang.ai/register/ and receive free API credits to start generating high-quality images immediately.
Last updated: May 28, 2025 This guide is regularly updated as new solutions and optimizations become available.