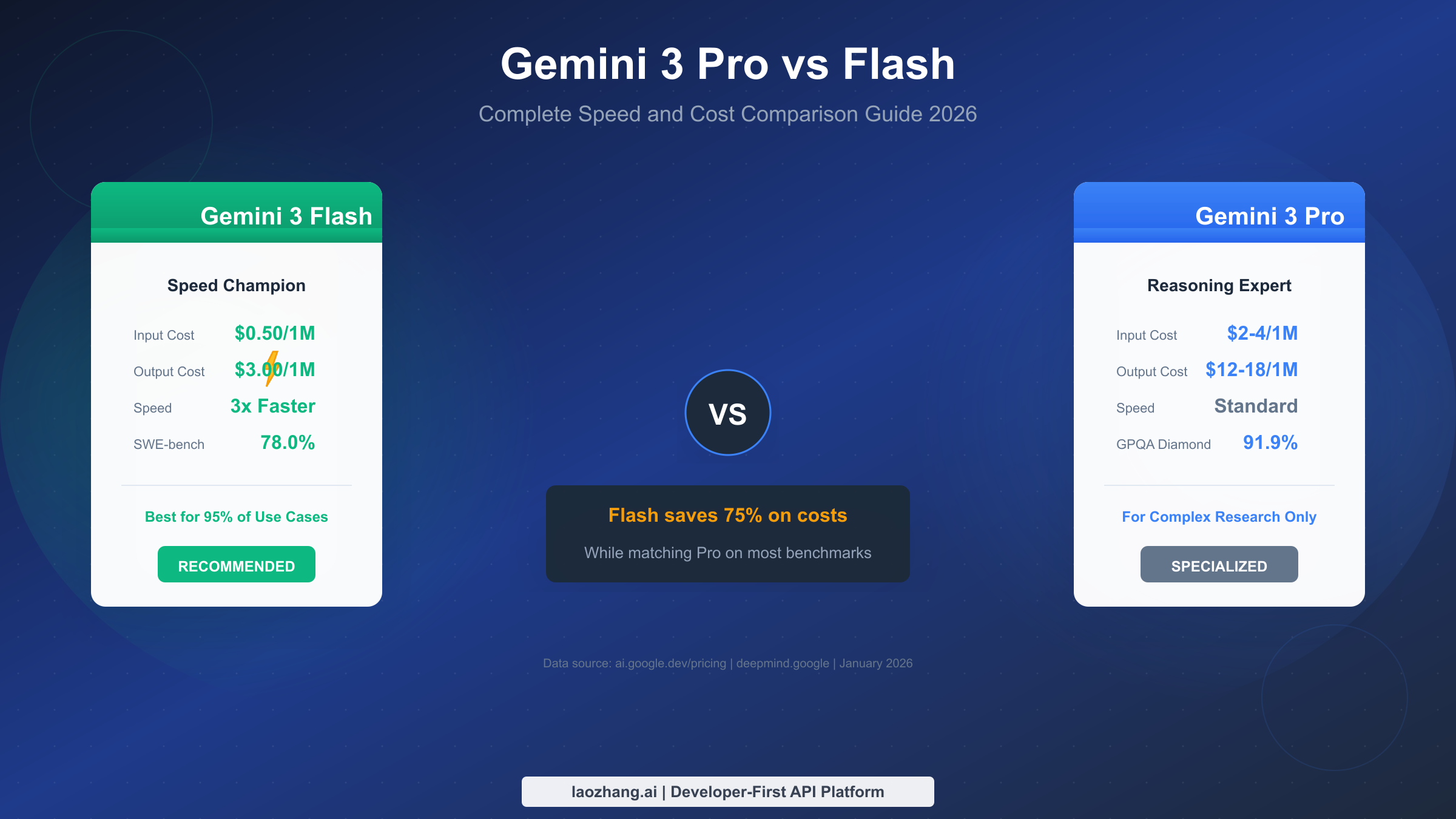
Gemini 3 Flash delivers 75% cost savings compared to Gemini 3 Pro while running 3x faster—and surprisingly outperforms Pro on coding benchmarks with 78% versus 76.2% on SWE-bench. For 95% of use cases including chatbots, coding assistants, and content generation, Flash is the optimal choice. Reserve Pro only for complex scientific research requiring the absolute maximum reasoning capability.
This guide provides everything you need to make an informed decision: complete pricing breakdowns, benchmark comparisons, real-world cost calculations, and a decision framework to match your specific use case.
TL;DR - The Bottom Line
Before diving into the details, here's the executive summary for busy developers. Gemini 3 Flash should be your default choice for most applications. It costs $0.50 per million input tokens compared to Pro's $2-4, outputs at $3 versus $12-18 per million tokens, and delivers responses approximately three times faster than Pro based on Artificial Analysis benchmarking.
The most surprising finding is that Flash actually outperforms Pro on coding tasks, achieving 78.0% on SWE-bench Verified compared to Pro's 76.2%. This means for the majority of developers building coding assistants, chatbots, or content generation systems, Flash offers better performance at a fraction of the cost.
Pro earns its premium only for frontier reasoning tasks—PhD-level research, novel scientific discoveries, or scenarios where you need the highest possible accuracy on the most difficult problems. On GPQA Diamond (graduate-level science reasoning), Pro scores 91.9% versus Flash's 90.4%, and on Humanity's Last Exam, Pro leads with 37.5% versus 33.7%.
The practical recommendation is straightforward: start with Flash. If you encounter specific use cases where Flash's output quality isn't meeting your requirements, selectively route those requests to Pro. This hybrid approach captures the best of both worlds while optimizing costs.
Complete Pricing Breakdown
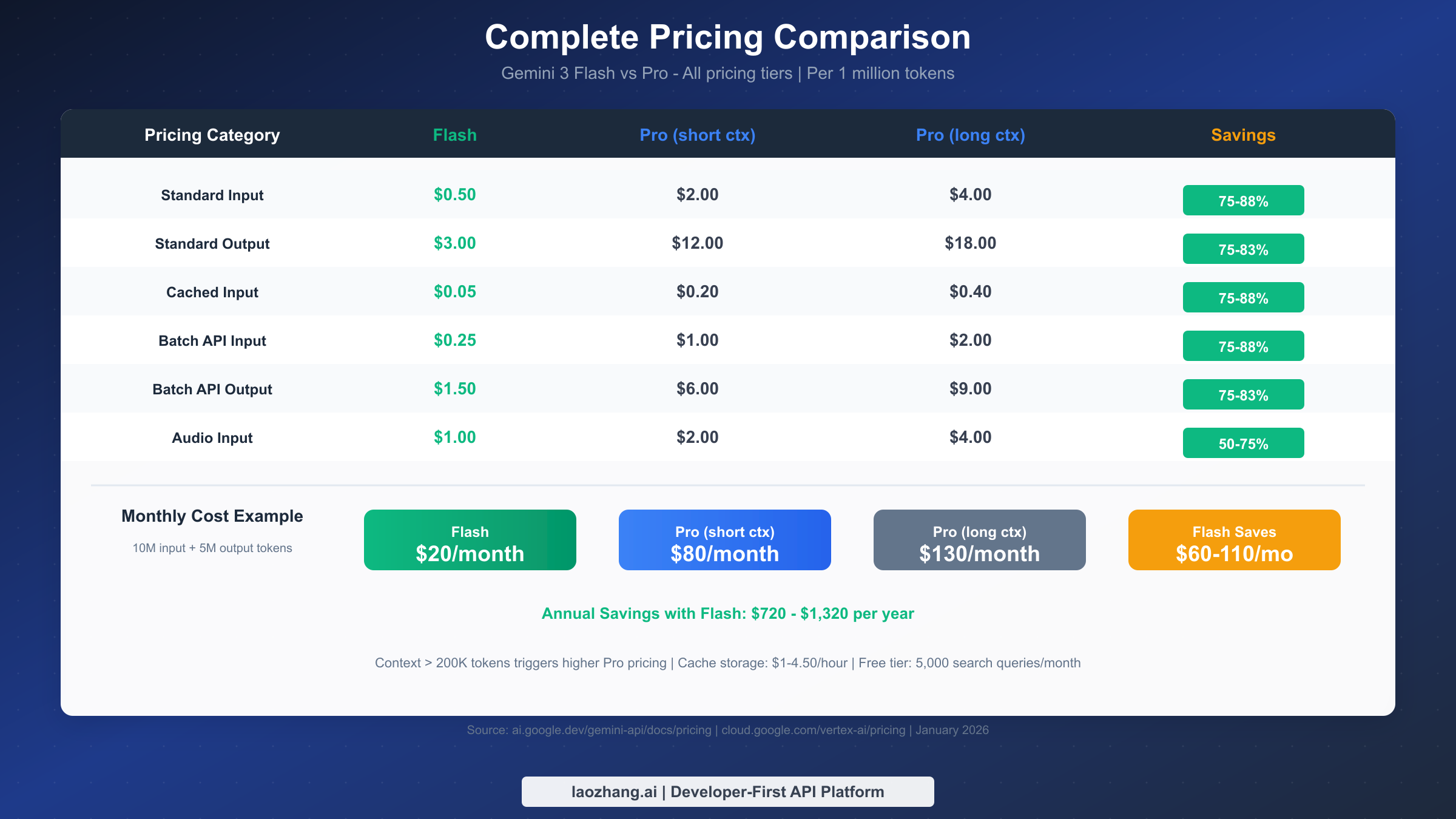
Understanding the full pricing structure is essential for accurate cost projections. Google's pricing varies by context length, caching status, and API type, so let's examine every tier as documented on the official Gemini API pricing page as of January 2026.
Standard API Pricing
The baseline pricing represents what most developers will encounter in typical usage scenarios. Flash charges $0.50 per million input tokens for text, images, and video, with audio inputs priced at $1.00 per million tokens. Output tokens cost $3.00 per million regardless of input modality.
Pro's pricing follows a tiered structure based on context length. For prompts under 200,000 tokens, Pro charges $2.00 per million input tokens and $12.00 per million output tokens. When your context exceeds 200K tokens—common when processing large documents or maintaining extensive conversation history—the rates increase to $4.00 per million input tokens and $18.00 per million output tokens.
This context-sensitive pricing reflects the computational complexity of maintaining attention across larger contexts. For most conversational applications staying well under 200K tokens, you're looking at the lower rates. But for document processing, code analysis, or long research sessions, budget for the higher tier.
Context Caching Pricing
Context caching provides dramatic savings for applications with repetitive prompts or system instructions. When you cache context with Flash, input token costs drop to just $0.05 per million tokens for short contexts or $0.10 for contexts exceeding 200K—representing a 90% reduction from standard rates. Storage costs $1.00 per hour per million cached tokens.
Pro's caching follows the same 90% discount pattern: $0.20 per million for short contexts, $0.40 for long contexts, with storage at $4.50 per hour per million tokens. While Pro's cached rates are higher in absolute terms, the percentage savings are identical.
For applications like customer support bots where you're sending the same system prompt with every request, caching transforms the economics entirely. A system prompt of 50,000 tokens sent 10,000 times monthly would cost $500 without caching versus $50 with caching—plus minimal storage costs if the cache is maintained continuously.
Batch API Pricing
The Batch API offers 50% discounts for asynchronous processing, ideal for offline analysis, bulk document processing, or any workload where immediate responses aren't required. Flash's batch pricing drops to $0.25 per million input tokens and $1.50 per million output tokens.
Pro's batch rates are $1.00 per million input tokens (short context) or $2.00 (long context), with outputs at $6.00 or $9.00 per million tokens respectively. For large-scale processing jobs, batch API can cut your costs in half compared to synchronous requests.
One important note: context caching for batch requests isn't yet implemented for Flash, though it's available for Pro. If you're planning batch workloads with repetitive contexts, factor this limitation into your cost calculations.
Cost Comparison Summary
To illustrate the real-world impact, consider processing 10 million input tokens and 5 million output tokens monthly—a moderate workload for a production chatbot or coding assistant.
With Flash standard pricing: (10 × $0.50) + (5 × $3.00) = $20 per month
With Pro standard pricing (short context): (10 × $2.00) + (5 × $12.00) = $80 per month
With Pro standard pricing (long context): (10 × $4.00) + (5 × $18.00) = $130 per month
Flash saves $60-110 monthly in this scenario, translating to $720-1,320 annually. For larger workloads, the savings scale proportionally—a 100M token/month operation would save $7,200-13,200 per year by choosing Flash over Pro.
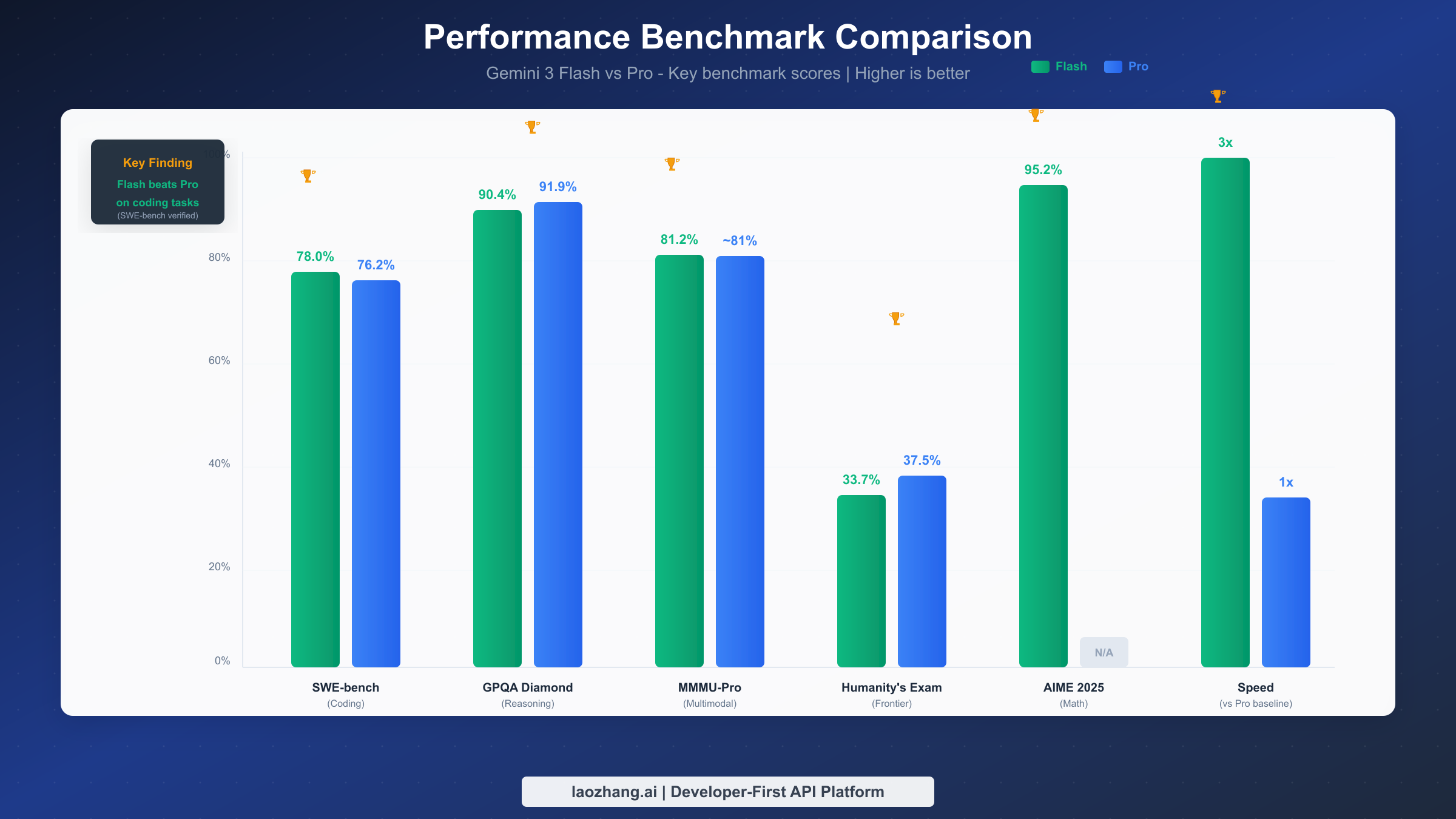
Speed and Performance Benchmarks
Performance comparisons reveal a nuanced picture where Flash and Pro each excel in different domains. Understanding these distinctions helps you match the right model to your specific requirements.
Speed Advantage
Flash's speed advantage is substantial and consistent across testing scenarios. According to Artificial Analysis benchmarking, Flash delivers approximately 3x the throughput with lower latency compared to Pro. In practical terms, Flash generates around 218 tokens per second and uses 30% fewer tokens on average than Gemini 2.5 Pro to accomplish the same tasks.
This speed differential matters enormously for real-time applications. A chatbot using Flash can respond to users in roughly one-third the time compared to Pro, directly impacting user experience and satisfaction. For coding assistants where developers expect rapid feedback, the latency improvement can be the difference between a productive tool and a frustrating one.
The efficiency gains also compound with token savings. If Flash uses 30% fewer tokens while also being 3x faster, you're getting more work done in less time at lower cost—a triple win for production applications.
Coding Benchmarks
Perhaps the most surprising finding is Flash's superiority on coding tasks. On SWE-bench Verified, the industry-standard benchmark for evaluating real-world coding ability, Flash achieves 78.0% compared to Pro's 76.2%. This isn't a marginal difference—Flash is definitively the better choice for software engineering tasks.
The LiveCodeBench results reinforce this finding, with Flash achieving an Elo rating of 2,316—placing it among the top coding models available. Flash's 541 Elo point lead on this benchmark suggests dramatically better algorithmic thinking and problem-solving capabilities.
For developers building coding assistants, code review tools, or automated programming systems, this data is decisive. Flash offers better coding performance at 25% of the cost, making Pro's premium entirely unjustifiable for these use cases. You can explore more Gemini 3 Flash vs Pro capabilities in our detailed feature comparison.
Reasoning Benchmarks
Pro's advantage emerges primarily on frontier reasoning tasks—the most challenging problems that push the boundaries of AI capabilities. On GPQA Diamond, which tests graduate-level scientific reasoning, Pro scores 91.9% versus Flash's 90.4%. While both scores are impressive, Pro maintains a slight edge.
The gap widens on Humanity's Last Exam, designed to test capabilities approaching the frontier of human expertise. Pro achieves 37.5% compared to Flash's 33.7%—a meaningful 3.8 percentage point difference that could matter for research applications.
On AIME 2025 (mathematical reasoning), Flash demonstrates exceptional capability with 95.2% accuracy without tools and an remarkable 99.7% with code execution enabled. This suggests Flash's mathematical abilities are highly developed despite its speed-optimized architecture.
For multimodal understanding, the models perform nearly identically. Flash scores 81.2% on MMMU-Pro while Pro achieves approximately 81%, indicating parity on visual reasoning tasks. Both outperform GPT-5.2's 79.5% on this benchmark, demonstrating Google's strong multimodal capabilities across their model lineup.
Understanding Flash's Limitations
While the performance and cost data strongly favor Flash for most applications, intellectual honesty requires discussing its limitations. One significant concern that most comparison articles fail to mention is Flash's hallucination behavior.
The Hallucination Challenge
According to testing by BetterStack, Gemini 3 Flash has a concerning 91% hallucination rate on certain factual knowledge tests. This doesn't mean Flash is wrong 91% of the time—it means that when Flash encounters questions it cannot answer correctly, it invents confident-sounding but incorrect answers over 90% of the time rather than admitting uncertainty.
Flash correctly answers 55% of factual knowledge questions, which demonstrates substantial capability. The problem is the confident fabrication on the remaining 45%. For applications where factual accuracy is critical and human verification isn't practical, this behavior pattern creates real risks.
Safe Use Cases for Flash
Flash excels in scenarios where outputs are verified, creativity is valued, or factual precision isn't mission-critical. Code prototyping and development workflows benefit from Flash's speed while relying on compilation and testing for verification. Creative content generation, brainstorming, and summarization tasks leverage Flash's strengths without exposing users to factual risks.
Real-time conversational applications where responses can be qualified with uncertainty indicators also work well. A customer support bot that prefaces uncertain answers with "Based on my understanding" or "I believe" can provide value while managing reliability expectations appropriately.
Dangerous Use Cases for Flash
Proceed with caution when considering Flash for factual question-answering systems where users expect definitive answers. Medical, legal, and financial advisory applications carry particular risk—confident but incorrect advice in these domains can cause real harm.
Customer support scenarios requiring precise policy information should either use Pro or implement robust verification layers. Any application where the AI's outputs directly influence decisions without human review should be carefully evaluated.
Mitigation Strategies
If you choose Flash for applications touching factual domains, implement verification layers. Cross-check factual claims against authoritative sources. Use confidence calibration techniques that detect when Flash is operating outside its reliable knowledge domains. Consider hybrid architectures where straightforward queries go to Flash while complex or factual queries route to Pro.
For development teams, the practical approach is: use Flash for speed-sensitive interactions, implement output validation, and selectively escalate to Pro when confidence thresholds aren't met. This balanced approach captures Flash's cost and speed benefits while managing reliability risks.
Real-World Cost Calculations
Abstract pricing becomes meaningful when applied to concrete scenarios. Let's examine four common deployment patterns with detailed cost projections.
Scenario 1: Customer Support Chatbot
A medium-sized e-commerce company handles 50,000 customer conversations monthly, with each conversation averaging 1,500 input tokens (customer query plus context) and 500 output tokens (bot response). Monthly token usage: 75M input tokens, 25M output tokens.
Flash costs: (75 × $0.50) + (25 × $3.00) = $37.50 + $75 = $112.50/month
Pro costs: (75 × $2.00) + (25 × $12.00) = $150 + $300 = $450/month
With Flash caching (assuming 20% cache hit rate on system prompts): approximately $95/month
Flash saves $337.50-355 monthly, or over $4,000 annually. For this high-volume, speed-sensitive application, Flash is the clear choice. If you're exploring API options for such applications, check our guide on Gemini API pricing and quotas.
Scenario 2: Coding Assistant for Development Team
A 20-developer team uses an AI coding assistant for code review, completion, and documentation. Each developer generates approximately 200,000 tokens of input and 100,000 tokens of output daily. Monthly usage: 120M input tokens, 60M output tokens.
Flash costs: (120 × $0.50) + (60 × $3.00) = $60 + $180 = $240/month
Pro costs: (120 × $2.00) + (60 × $12.00) = $240 + $720 = $960/month
With Flash batch API (for non-urgent code analysis): approximately $120/month
Given Flash's superior coding benchmark performance, choosing Pro would mean paying 4x more for worse results. Flash is unambiguously the right choice for coding applications.
Scenario 3: Research Document Analysis
A research institution processes academic papers for literature review. Monthly workload: 5M input tokens (document content), 2M output tokens (summaries and analysis). Documents regularly exceed 200K tokens, triggering Pro's higher tier.
Flash costs: (5 × $0.50) + (2 × $3.00) = $2.50 + $6 = $8.50/month
Pro costs (long context): (5 × $4.00) + (2 × $18.00) = $20 + $36 = $56/month
For research requiring maximum reasoning capability and working with long documents, Pro's premium might be justified. However, Flash at $8.50 monthly versus Pro at $56 means Flash is 85% cheaper. Unless the reasoning quality difference is critical for your research outcomes, Flash provides excellent value.
Scenario 4: Batch Document Processing
A legal firm processes 10,000 contracts monthly for clause extraction and summarization. Each contract averages 8,000 tokens with 2,000 tokens of extracted output. Batch processing is acceptable since results aren't needed in real-time.
Monthly usage: 80M input tokens, 20M output tokens (batch eligible).
Flash batch costs: (80 × $0.25) + (20 × $1.50) = $20 + $30 = $50/month
Pro batch costs: (80 × $1.00) + (20 × $6.00) = $80 + $120 = $200/month
Batch processing cuts Flash costs in half, making it 4x cheaper than Pro batch rates. For any batch-eligible workload, the economics strongly favor Flash with batch API.
Platform Alternatives for Cost Optimization
For teams seeking additional cost optimization, API aggregation services like laozhang.ai can provide further savings while simplifying multi-model deployments. These platforms often offer unified billing, simplified authentication, and additional features like automatic failover between models.
Use Case Decision Framework
Making the right choice requires matching model capabilities to your specific requirements. Rather than prescribing a single answer, here's a framework for reasoning through your decision.
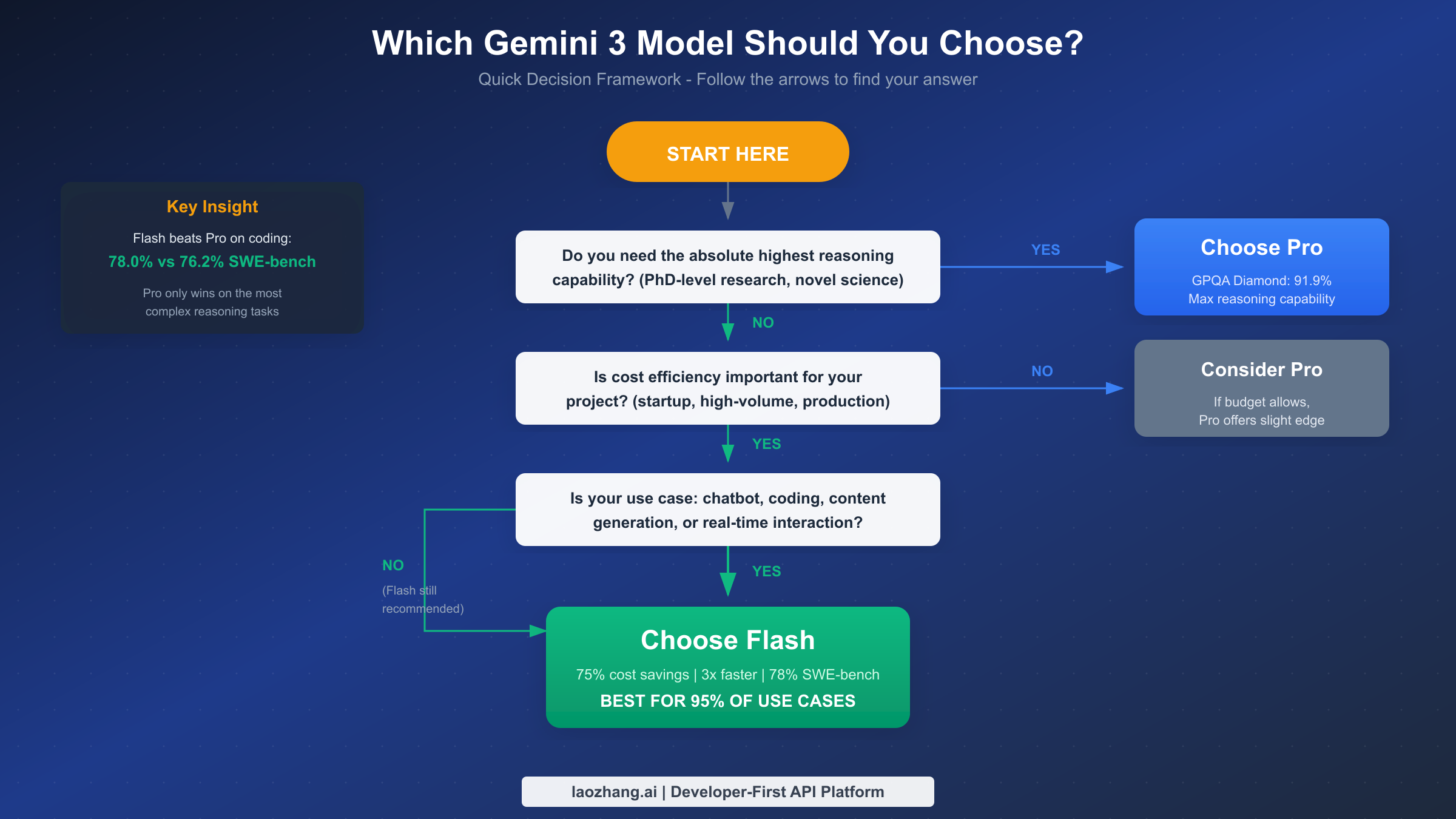
Choose Flash For (Recommended Default)
Flash should be your default choice for real-time conversational applications where response speed impacts user experience. Chatbots, virtual assistants, and interactive tools all benefit from Flash's 3x speed advantage while achieving comparable or better quality for typical conversational tasks.
Coding and development workflows favor Flash unambiguously given its benchmark superiority. Code completion, review, explanation, refactoring, and documentation generation all perform better with Flash while costing 75% less.
High-volume production systems should use Flash to optimize unit economics. At scale, the 75-88% cost savings compound into meaningful budget reductions that can fund additional features or expanded capacity.
Content generation, summarization, and creative writing tasks leverage Flash's speed without requiring Pro's reasoning depth. Marketing copy, email drafts, article summaries, and creative brainstorming all work excellently with Flash.
Rapid prototyping and experimentation benefit from Flash's cost structure. When iterating quickly on prompts or testing new applications, Flash's lower per-request cost enables more experimentation within the same budget.
Choose Pro For
Pro earns its premium for frontier reasoning tasks requiring absolute maximum accuracy. PhD-level research, novel scientific analysis, and problems pushing the boundaries of AI capability may benefit from Pro's slight reasoning edge on the hardest benchmarks.
Maximum context utilization scenarios where you're consistently working near the 1M token limit might favor Pro. However, note that Flash also supports 1M token contexts, so this advantage is marginal.
Quality-critical applications where errors carry significant consequences should consider Pro. Medical research analysis, legal document review requiring maximum accuracy, and safety-critical applications might justify Pro's premium as an insurance policy against edge-case failures.
The Hybrid Approach
The most sophisticated deployment strategy routes requests intelligently between models. Start all requests with Flash, measure output quality through automated evaluation or user feedback, and selectively escalate to Pro when quality thresholds aren't met.
For implementation, define quality heuristics based on your domain: response confidence scores, user satisfaction ratings, task completion rates, or domain-specific metrics. Route the small percentage of requests that underperform to Pro while capturing Flash's benefits for the majority.
This approach typically uses Flash for 90-95% of requests while reserving Pro for the 5-10% requiring maximum capability. You capture most of Flash's cost savings while ensuring quality never falls below acceptable thresholds.
Hybrid Deployment Strategy
Implementing a smart routing system between Flash and Pro can optimize both cost and quality. Here's how to architect such a system.
Routing Logic Principles
The simplest approach routes based on request characteristics detectable before processing. Query complexity indicators—long prompts, technical vocabulary, multi-step reasoning requirements—can trigger Pro routing. User tier or account type can determine model selection, with premium users getting Pro access by default.
More sophisticated routing uses Flash as the primary model with quality-based escalation. Process the initial request with Flash, evaluate output quality using automated metrics, and re-process with Pro if quality falls below threshold. This adds latency for escalated requests but ensures consistent quality while maximizing cost efficiency.
pythondef select_model(request): # Route to Pro for explicitly complex tasks if request.complexity_score > 0.8: return "gemini-3-pro-preview" # Route to Pro for premium users if request.user.tier == "enterprise": return "gemini-3-pro-preview" # Default to Flash return "gemini-3-flash-preview" def process_with_fallback(request): # Try Flash first response = call_flash(request) # Check quality metrics if response.confidence < 0.7 or response.quality_score < threshold: # Escalate to Pro response = call_pro(request) return response
Implementation Considerations
Latency management becomes important with quality-based escalation. Consider async processing where possible—send the Flash request, begin response streaming, and only block for Pro escalation if quality metrics trigger during generation.
Cost tracking should monitor per-model usage to validate that your routing logic achieves expected savings. Track escalation rates to identify patterns where Flash consistently underperforms, which might indicate opportunities to improve prompts or adjust routing thresholds.
Quality feedback loops improve routing over time. Log which requests escalated to Pro and whether Pro's output was measurably better. This data refines your complexity detection and escalation thresholds.
For teams wanting simplified hybrid deployments, unified API platforms can abstract the routing complexity. Services that aggregate multiple models behind a single endpoint reduce the engineering overhead of maintaining connections to multiple APIs while enabling sophisticated routing without building the infrastructure from scratch.
How Gemini 3 Compares to Competitors
Context helps evaluate Gemini 3's positioning against other frontier models. Here's how Flash and Pro stack up against OpenAI and Anthropic offerings.
Versus GPT-5.2
On Humanity's Last Exam without tools, Flash scored less than a percentage point worse than GPT-5.2—remarkable parity for a speed-optimized model. On MMMU-Pro multimodal reasoning, Flash achieved 81.2% versus GPT-5.2's 79.5%, actually outperforming OpenAI's flagship.
Pricing comparison favors Gemini for most use cases. GPT-5 charges $1.25 per million input tokens versus Flash's $0.50—making Flash 60% cheaper on input. Output pricing at $3 for Flash versus $10 for GPT-5 represents 70% savings.
For developers currently using GPT models, Flash offers comparable or better performance on many benchmarks at substantially lower cost. The 1M token context window also exceeds GPT-5's limits, providing additional flexibility for long-document processing.
Versus Claude 4.5
Anthropic's Claude 4.5 Opus achieves 80.9% on SWE-bench—slightly above Flash's 78% but at dramatically higher cost. Opus charges $5 per million input tokens and $25 per million output tokens, making it 10x more expensive than Flash on input and 8x more on output.
Claude Sonnet 4.5 at 77.2% SWE-bench is priced at $3 per million input tokens—still 6x Flash's cost for marginally lower coding performance.
For pure coding tasks, Flash offers the best value proposition among frontier models: competitive performance at the lowest price point. For applications requiring Claude's specific capabilities (extensive training on safety, particular reasoning patterns), Claude remains relevant, but Flash has emerged as the cost-efficiency leader.
Gemini's Unique Advantages
Gemini 3's 1M token context window exceeds most competitors, enabling long-document processing that would require chunking with other models. The unified multimodal architecture handles text, images, video, and audio natively, simplifying applications that work with diverse content types.
Google's integration ecosystem—connection to Search, Maps grounding, and other Google services—provides unique capabilities for applications needing real-time information or location awareness. The 5,000 free monthly search grounding queries included with the API add substantial value for applications requiring current information.
For comprehensive pricing information across all Gemini models, see our complete Gemini API pricing guide for 2026.
Getting Started and Final Recommendations
With the analysis complete, here's your practical roadmap for implementing Gemini 3 in your applications.
Quick Start Steps
First, create a Google AI Studio account at ai.google.dev if you don't already have one. Generate an API key from the console—the free tier provides enough quota to thoroughly test both Flash and Pro before committing to paid usage.
Start with Flash for all initial development. Use the model ID gemini-3-flash-preview in your API calls. Test your specific use cases and measure quality against your requirements. Only consider Pro if Flash demonstrably underperforms for critical functionality.
python# Basic API call example import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3-flash-preview") response = model.generate_content("Your prompt here") print(response.text)
Recommended Configuration
For production deployments, implement context caching for any system prompts or repeated context exceeding 10,000 tokens. The 90% input cost reduction pays for the storage overhead quickly with moderate request volume.
Enable thinking mode when reasoning quality matters—Flash supports configurable thinking levels (minimal, low, medium, high) that trade speed for reasoning depth. For complex analytical tasks, medium or high thinking can bridge much of the gap with Pro.
Consider batch API for any workload that doesn't require real-time responses. Nightly processing jobs, bulk analysis, and background tasks can all leverage 50% batch discounts without impacting user experience.
Final Recommendations
For developers building new applications: Start with Flash. Its combination of speed, cost, and performance—especially on coding tasks—makes it the optimal default choice. Only introduce Pro if you identify specific use cases where Flash's output quality is demonstrably insufficient.
For teams migrating from other models: Flash likely matches or exceeds your current model's performance at lower cost. The 1M token context and native multimodal support may enable new capabilities your current architecture can't support.
For cost-conscious organizations: Flash's 75-88% cost savings over Pro—and competitive pricing versus alternatives—make it the economical choice without sacrificing quality for most applications.
For research and frontier applications: Pro remains relevant for the most challenging reasoning tasks. But even here, a hybrid approach using Flash for routine work and Pro for critical analysis optimizes spend while maintaining capability.
The data is clear: Gemini 3 Flash has shifted the landscape by delivering Pro-grade capabilities at Flash-grade prices. For the vast majority of developers and applications, Flash is no longer the budget alternative—it's the recommended choice.