
If your Claude API response is HTTP 500 with error.type set to api_error, start as if the request reached Claude and failed inside the service. Check Claude Status first, save the response request_id or request-id header, and keep the same model, endpoint, auth owner, SDK or gateway route, network path, and request shape until you have proof.
On May 19, 2026, Claude Status showed all systems operational, with recent resolved elevated-error incidents still visible. That dated status check narrows the incident branch; it does not prove your exact model, account, region, gateway, or workload is local-only. Use it as the first branch test, then retry only with a small safe budget.
Use this first-screen recovery board before changing keys, prompts, models, providers, or browser settings.
| What you have | First action | Verify | Stop rule |
|---|---|---|---|
Clean HTTP 500 with api_error | Save request_id, timestamp, model, endpoint, and route, then check Claude Status | The same request path either recovers or repeats with the same branch | Stop after a small bounded retry budget; do not loop indefinitely |
529 overloaded_error | Treat it as capacity pressure, reduce retry pressure, and wait or lower concurrency | The error changes or clears after backoff and reduced load | Do not diagnose it as your own validation bug |
429 rate_limit_error | Inspect usage, pacing, and quota before retrying | Requests succeed after pacing, batching, or limit adjustment | Do not rotate keys as a default 500 fix |
504 timeout_error or a long request | Shorten, stream, batch, or tune timeout-aware request design | A smaller or streaming request completes on the same account | Do not call it a clean internal-server branch without the 500 response |
| Connection, DNS, proxy, TLS, or SDK timeout before a response | Test the network path, base URL, proxy, firewall, and SDK timeout separately | A known-small request reaches the API and returns a normal response or a clearer error | Do not apply API 500 retry rules to a connection failure |
| Repeated clean 500s on the same path | Build an escalation packet with request IDs, status timestamp, retry timeline, route owner, and a redacted reproduction shape | Support or the platform owner can correlate the same failing path | Do not send secrets, full prompts, auth headers, or private user data |
Stop once one branch gives evidence. If the same path keeps returning clean 500s after the bounded retry budget, escalate with the evidence packet instead of rewriting the request, switching providers, or changing several variables at once.
What a clean 500 api_error means
Anthropic's API error documentation maps HTTP 500 to api_error. That is the official branch owner: the request reached the API layer, the service returned an internal error, and the response may include a JSON body with error.type, error.message, and a response-level request_id. Anthropic also documents a request-id response header on API responses, which is why the first operational habit is evidence capture rather than guesswork.
That does not mean every 500 is identical. A transient internal service error, a model-specific incident, an upstream dependency issue, and a routed gateway problem can all appear to the caller as a returned 500. The useful distinction is not "Claude is broken" versus "my code is broken." The useful distinction is whether the same path can be reproduced, whether status or recent incidents explain the timing, and whether changing local variables actually changes the outcome.
Do not begin with key rotation. A bad key normally produces an authentication or permission branch, not a clean internal server error. Do not begin with prompt rewriting either. A malformed request should normally be a 4xx branch. Prompt and payload shape can still matter if the request is huge, non-repeatable, or mixed with tool calls, but those are second-order checks after the status, identifiers, and same-path proof are preserved.
Claude Code deserves special mention because the search page often mixes API and Claude Code results. Anthropic's Claude Code error documentation says Claude Code may show raw 5xx response bodies, and it classifies 500 as an Anthropic-side infrastructure or API failure. That makes Claude Code a surface where the same API branch can become visible, not a separate root cause by default.
Match the branch before you fix it
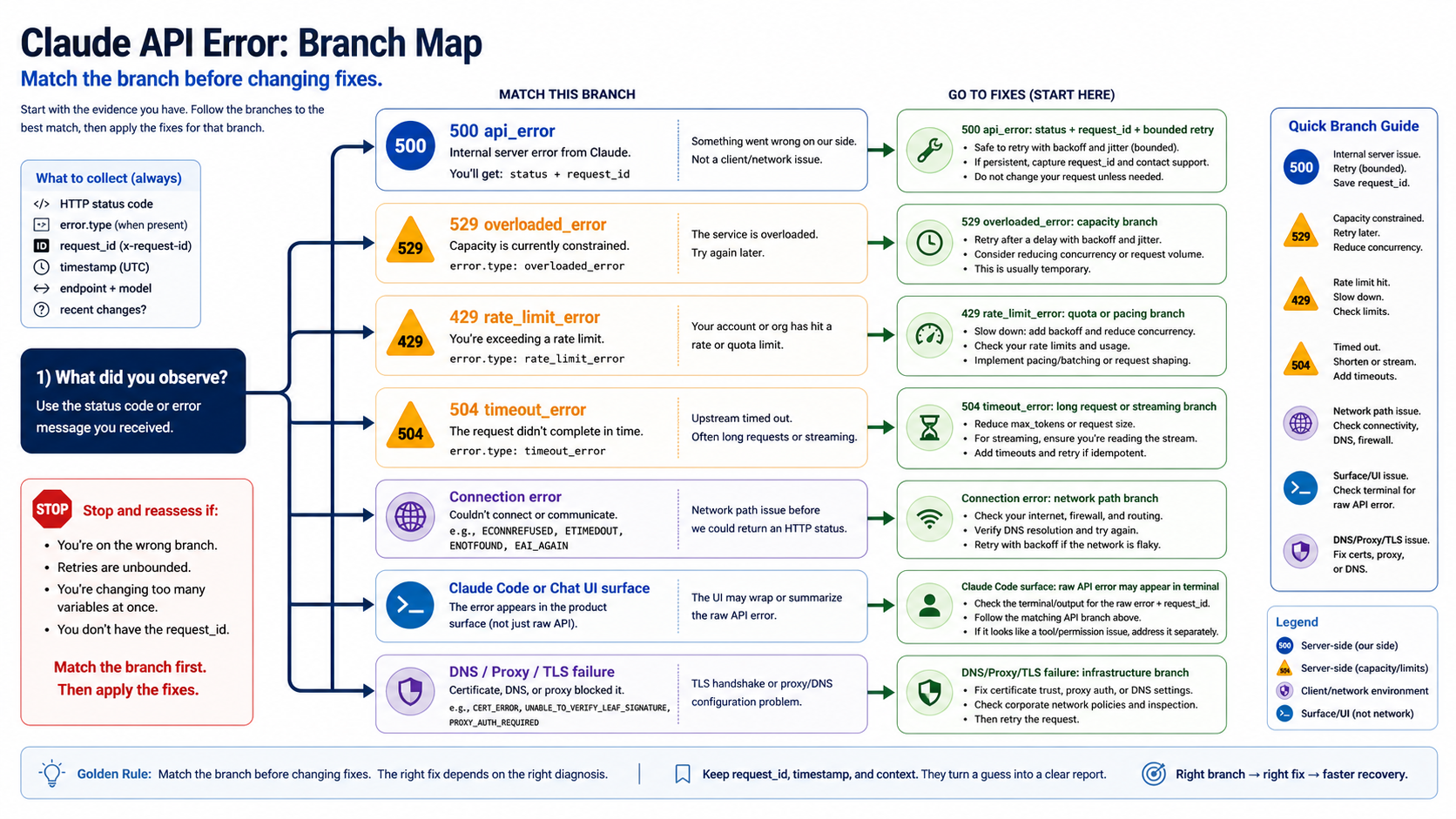
The fastest way to waste time is to use the right-looking fix on the wrong branch. 500 api_error, 529 overloaded_error, 429 rate_limit_error, 504 timeout_error, and connection-layer failures can all interrupt the same product workflow, but they ask for different operator behavior.
Use 500 api_error when you have a returned HTTP response from Claude and the error body identifies the internal server branch. The response itself is the signal: status, request ID, model, endpoint, and route become the important evidence. The first recovery move is status plus bounded retry, not usage-plan math.
Use 529 overloaded_error when the service says capacity is constrained. That branch needs pressure reduction and retry-storm prevention. If the error changes to 529, the more precise sibling page is Claude 529 Overloaded Error; the operational emphasis shifts from internal-error evidence to capacity behavior and retry load.
Use 429 rate_limit_error when the account or organization is being paced or limited. That branch is not solved by waiting for a provider incident unless a status incident also exists. Inspect limits, usage shape, concurrency, token volume, and retry headers. For a dedicated rate-limit path, use Claude API 429 error recovery.
Use 504 timeout_error when the request does not complete in time. Long-running work may need streaming, Message Batches, smaller request shape, or timeout-aware client handling. Treating a timeout as a clean 500 can hide the real fix: the service may need a different execution mode rather than another blind retry.
Use the connection branch when there is no returned API response at all. DNS, proxy, TLS, firewall, VPN, base URL, corporate inspection, and SDK timeout problems can fail before Claude has a chance to return api_error. In that case, a tiny known-good request, a second network path, and clean base URL verification matter more than Claude Status.
Run the bounded recovery loop

The recovery loop is deliberately short: status, evidence, bounded retry, same path, stop or escalate. Each step exists because it prevents a common operational mistake.
First, check Claude Status and record the timestamp. An active incident changes the next move: wait, protect users, and reduce repeat pressure. A clear status page does not prove your path is local-only, but it does make same-path evidence more important. If your logs show a spike that matches a recent incident window, preserve that correlation instead of erasing it with repeated code changes.
Second, save the identifiers. In direct API calls, capture the response request_id when it appears and the request-id header when available. In SDKs, also save the exception class, HTTP status, model, endpoint, base URL, route owner, SDK version, and your own correlation ID. In Claude Code or routed workflows, keep the raw error body if the tool exposes it. The goal is to turn "Claude returned 500 again" into a supportable event.
Third, retry only with a small budget. Two or three SDK-level attempts may already be happening before your application code sees the failure, depending on the client. Adding an unbounded outer loop can multiply side effects and worsen a provider incident. Use backoff and jitter, cap total elapsed time, and stop when the same clean 500 keeps repeating.
Fourth, verify the same path. "Same path" means the same model, endpoint, auth owner, SDK or gateway route, base URL, network path, headers minus secrets, and request shape. If you change several variables at once and the next request succeeds, you do not know whether Claude recovered, the route changed, or the request stopped triggering the same branch.
Fifth, decide between stop and escalation. If one bounded retry succeeds and your workflow is idempotent, record the event and keep monitoring. If repeated clean 500s continue on the same path, stop changing the request and build the escalation packet.
Make retries safe before repeating work
A 500 retry is only safe when repeating the operation is safe. Read-only prompts, summarization calls, and deterministic analysis jobs are usually easier to retry. Jobs that trigger payments, write records, send messages, update tickets, start tool calls, or create files need idempotency protection before another attempt.
For user-facing applications, separate "the model call failed" from "the workflow side effect happened." If your code writes to a database before the model call, make the write idempotent. If a tool call can send an email or trigger a purchase, do not rerun the whole chain just because the final model response returned 500. Store a job ID, deduplicate on replay, and show a clear degraded-state message to the user.
Retry budgets should also be visible to operators. A useful policy has four numbers: maximum attempts, initial delay, backoff shape, and maximum elapsed time. A short incident can recover inside that budget; a persistent incident should trip a stop rule. Without those numbers, "retry with backoff" becomes a vague instruction that each engineer implements differently.
Here is the shape of a conservative handler. It is not meant to be copied blindly into every stack; it shows the branch boundaries that matter.
tsasync function callClaudeWith500Budget(runClaude: () => Promise<unknown>) { const maxAttempts = 3; const baseDelayMs = 800; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await runClaude(); } catch (error: any) { const status = error?.status || error?.statusCode; const type = error?.error?.type || error?.type; if (status !== 500 || type !== "api_error") { throw error; } recordClaude500Evidence({ attempt, requestId: error?.request_id || error?.headers?.["request-id"], status, type, }); if (attempt === maxAttempts) { throw error; } const jitter = Math.floor(Math.random() * 400); await sleep(baseDelayMs * 2 ** (attempt - 1) + jitter); } } }
The important behavior is not the exact delay. The important behavior is that the handler refuses to treat every error as retryable, records request evidence before sleeping, and stops after a bounded budget.
Keep route owners separate
Route ownership is where many 500 incidents become confusing. A direct Anthropic API call, a Claude Code terminal flow, a Workbench test, a hosted gateway, a corporate proxy, and a browser chat surface may all end in a similar human experience: "Claude failed." They are not the same operational route.
In a direct API route, Anthropic owns the service response and your team owns request construction, retry policy, idempotency, and log capture. In Claude Code, the terminal can expose the raw API error, but local auth state, tool execution, MCP servers, and CLI updates can still add their own failure layer. In a gateway route, the gateway owns base URL, authentication handoff, provider selection, logging, and sometimes retry behavior before the request reaches Anthropic.
That is why same-path verification includes the route owner. If a direct Anthropic request fails with clean 500 but the same payload succeeds through a gateway, the evidence is useful, but it does not prove Anthropic is healthy or unhealthy in isolation. It proves that one route has a different outcome. Keep the original failing request ID, gateway request ID, base URL, and timestamp separated so the owner of each layer can investigate the right event.
Avoid switching providers as the first fix. It may be a valid availability strategy for production systems, but it destroys the diagnostic line if you do it before collecting evidence. First preserve the original failure, then decide whether business continuity requires a fallback route. A fallback should be an operational design choice, not a panic click after one 500.
Build the escalation packet

Escalation works best when the packet lets the receiving team correlate the failing path without exposing secrets. Do not send API keys, bearer tokens, auth headers, full private prompts, customer PII, raw files, or confidential business data. Send metadata, redacted shape, and request identifiers.
The minimum packet is:
| Field | Why it matters |
|---|---|
| Status timestamp | Shows whether the failure aligns with a public incident or a green-status window |
request_id or request-id | Lets the provider or platform owner trace the specific response |
HTTP status and error.type | Confirms this is the 500 api_error branch, not 429, 529, 504, or connection failure |
| Model and endpoint | Separates model-specific incidents from route or account problems |
| SDK, gateway, base URL, and region when relevant | Identifies the layer that may have wrapped or routed the request |
| Retry timeline | Shows whether the error persisted after bounded backoff |
| Same-path reproduction | Proves the failure repeats without changing variables |
| Redacted payload shape | Shows request size, tool usage, streaming mode, and attachment class without leaking secrets |
| Impact and frequency | Helps support prioritize one-off noise versus production degradation |
If the issue is happening inside Claude Code, include the Claude Code version, command shape, whether the raw 5xx body appeared in the terminal, whether the same task fails in Workbench or direct API, and whether auth or login symptoms appear at the same time. If it is happening through a gateway or internal service, include both the gateway trace ID and any Anthropic request ID the route exposes.
The packet should be short enough to read and complete enough to correlate. A concise timeline is usually better than a long narrative: first failure time, status check time, attempts, same-path reproduction, current impact, and what changed recently.
Production controls for recurring 500s
Teams that depend on Claude should not discover their 500 policy during an incident. The first control is structured logging. Every failed request should keep status, error type, request ID, model, endpoint, route owner, elapsed time, attempt number, and your own correlation ID. Without those fields, incident review becomes a memory exercise.
The second control is a circuit breaker. If clean 500s spike above a threshold, pause high-volume non-critical jobs, protect user-facing workflows with a clear degraded-state message, and reduce retry pressure. The goal is not to abandon Claude after one internal error; the goal is to stop turning a provider-side problem into your own traffic storm.
The third control is idempotent job design. Queue work that can wait, deduplicate jobs that can replay, and mark non-repeatable actions before the model call begins. If the model call is only one step inside a larger workflow, do not make the whole workflow repeat automatically without replay protection.
The fourth control is route isolation. Keep direct API failures, gateway failures, Claude Code failures, and browser-product failures in separate dashboards. A green line in one route should not mask a red line in another. This matters especially for teams using multiple tools on top of Anthropic because a wrapper can convert one branch into another-looking error.
The fifth control is a documented escalation owner. Decide who checks Claude Status, who owns the first support ticket, who can reduce concurrency, who can switch to a fallback route, and who communicates with users. The worst incident process is five people changing five variables while no one preserves the first request IDs.
FAQ
Does a Claude API 500 mean my prompt is invalid?
Usually no. A clean HTTP 500 with api_error is the internal-server branch. Invalid prompts, malformed JSON, auth failures, and permission issues should normally show up as different branches. Keep the request evidence first, then inspect prompt size or tool shape only after the branch is preserved.
Should I rotate my API key?
Not as the default fix. Key rotation belongs to auth, permission, or suspected-secret-exposure branches. If the response is clean 500 api_error, rotating keys can erase useful evidence and create a second variable. Save the request ID and verify the same path before touching credentials.
How many retries are safe?
Use a small bounded budget, not an unlimited loop. A common starting point is two or three application-level attempts with backoff and jitter, adjusted for whether the SDK already retried. Stop sooner for non-idempotent workflows and escalate when the same path keeps returning clean 500s.
Does green Claude Status mean the bug is local?
No. Green status is a dated branch signal, not proof that your exact model, account, region, route, or workload is healthy. It means you should preserve same-path evidence and avoid assuming an active public incident explains the failure.
Is 500 api_error the same as 529 overloaded_error?
No. Both can feel like provider-side failure, but they are separate official branches. 500 api_error is an internal server error branch. 529 overloaded_error is a capacity or overload branch. If the error body says 529, treat pressure reduction and retry load as the main issue.
Can Claude Code show this same error?
Yes. Claude Code can surface raw API 5xx responses, so a terminal error can still be the same returned API branch. Keep the raw response body, request ID if present, command context, and route evidence. Then separate Claude Code auth or local-tool symptoms from the underlying API response.
When should I contact support or escalate internally?
Escalate after repeated clean 500s on the same path, after a bounded retry budget, or when user-facing impact is material. Include status timestamp, request IDs, model and endpoint, route owner, retry timeline, redacted payload shape, and impact. Do not send secrets or full private prompts.
Should I switch providers when Claude returns 500?
Only after you preserve the original failure evidence. A fallback route can be the right business-continuity choice for production, but switching immediately prevents diagnosis. Treat fallback as an operational policy, not a substitute for request IDs, status checks, and same-path verification.